7. 请问如何为Agent设计短期记忆和长期记忆系统?可以借助哪些外部工具或技术?
1. 题目分析
这道题非常有深度,它不是在问一个简单的概念定义,而是在考察你对 Agent 架构设计的实战理解。面试官想听到三个层次的东西:第一,你对短期记忆和长期记忆的定义和区别有没有清晰的认知;第二,你知不知道每种记忆具体怎么实现,背后用了什么技术;第三,也是最容易拉开差距的——你有没有在实际项目中处理过记忆相关的工程问题,比如上下文窗口不够用怎么办、长期记忆怎么存怎么检索。能把这三层讲通,面试官基本就能判定你是真的做过 Agent 而不是只看过文档。
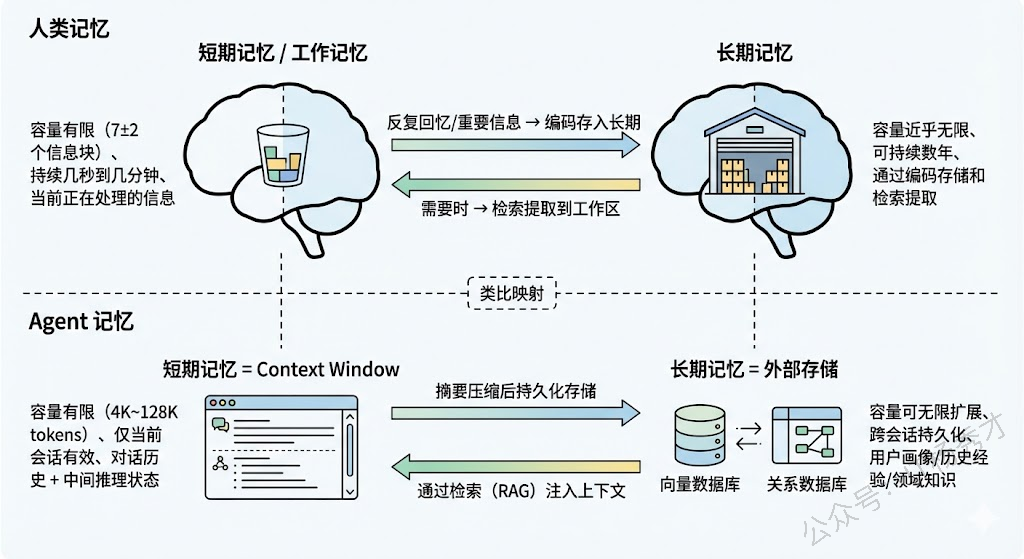
1.1 先理解人类记忆的类比
Agent 的记忆系统设计其实是从认知科学中借鉴过来的。人类的记忆大致分为两类:一类是短期记忆(Short-term Memory),也叫工作记忆,容量有限,持续时间短,比如你听到一个手机号码,能暂时记住但过一会儿就忘了;另一类是长期记忆(Long-term Memory),容量几乎无限,能持续很长时间,比如你的名字、骑自行车的技能、上周开会的内容。
把这个类比映射到 Agent 身上就非常自然了:Agent 的"短期记忆"对应的是当前对话的上下文信息,它是临时的、有容量限制的;Agent 的"长期记忆"对应的是跨对话持久化存储的知识和经验,它需要额外的存储系统来承载,理论上可以无限扩展。
理解了这个映射关系,后面的所有技术方案都好理解了——短期记忆的核心问题是"上下文窗口有限怎么办",长期记忆的核心问题是"信息怎么存、怎么检索、怎么更新"。
1.2 短期记忆:上下文窗口的管理艺术
Agent 的短期记忆,最直接的载体就是 LLM 的 Context Window(上下文窗口)。每次调用 LLM 时,我们把之前的对话历史、系统提示词、工具调用记录等信息拼接成一个 prompt 发给模型,模型就是基于这些"短期记忆"来理解当前状态并做出决策的。
问题在于,Context Window 的容量是有限的。即使现在的模型已经支持 128K 甚至更长的上下文,在实际 Agent 场景中,上下文很容易就被撑满——一个复杂任务可能需要十几轮工具调用,每轮的 Thought、Action、Observation 加起来可能就有上千 token,再加上系统提示词和工具定义,上下文窗口很快就不够用了。而且即使窗口足够大,研究表明模型在处理超长上下文时会出现"Lost in the Middle"现象——对上下文中间位置的信息关注度明显下降。
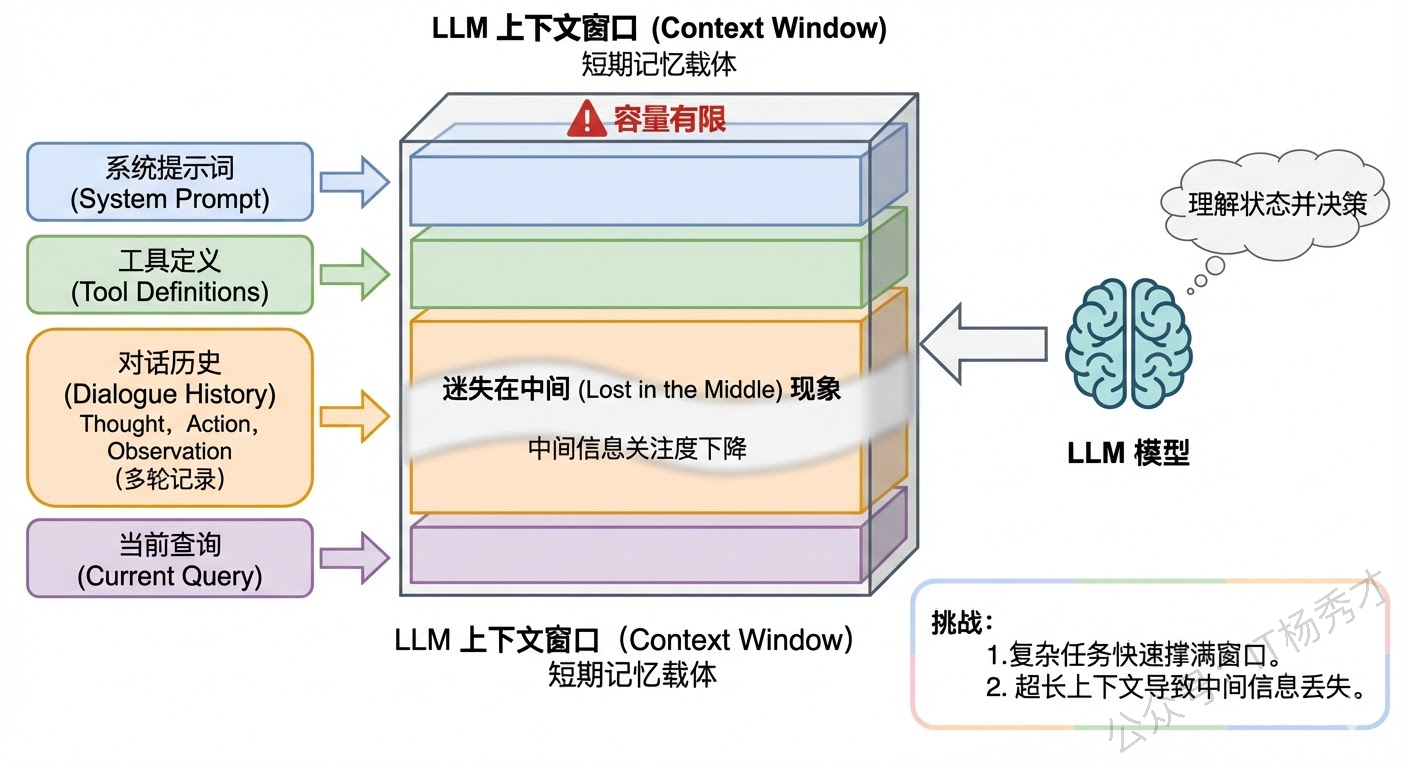
所以短期记忆的核心挑战是:如何在有限的上下文窗口里,尽可能保留最有用的信息? 这就衍生出了几种主流的管理策略:
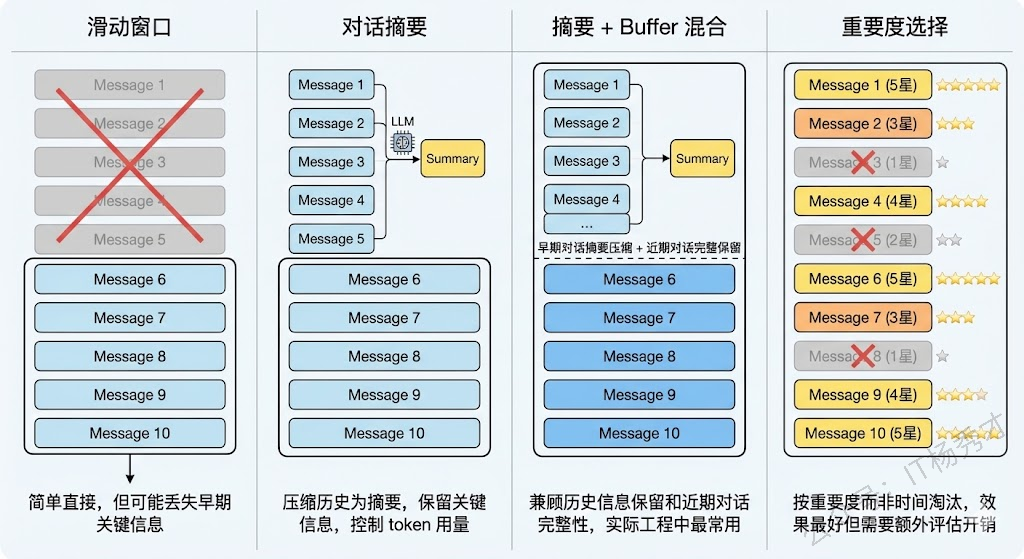
滑动窗口(Sliding Window) 是最简单粗暴的方案。当对话历史超过窗口限制时,直接截断最早的消息,只保留最近的 N 轮对话。这种方法实现简单但信息丢失严重——可能用户在第一轮告诉了 Agent 一个关键信息,到了第十轮就被截掉了,Agent 完全"忘"了这件事。
对话摘要(Conversation Summary) 是一种更优雅的方案。当对话历史变长时,不是直接截断,而是用 LLM 把较早的对话内容压缩成一段摘要,然后用这段摘要替代原始的冗长历史。这样既控制了 token 用量,又保留了关键信息。LangChain 中的 ConversationSummaryMemory 和 ConversationSummaryBufferMemory 就是这种策略的实现——后者更实用一些,它保留最近几轮的原始对话不动,只对更早的对话做摘要压缩,兼顾了近期对话的完整性和历史信息的保留。
Token Buffer(Token 缓冲区) 则是按 token 数量来精确控制。设置一个 token 上限,比如 4000 token,当历史消息的总 token 数超过这个值时,从最早的消息开始逐条丢弃,直到总量回到阈值以内。这种方式比简单的轮次截断更精确,但本质上还是"先进先出"的淘汰策略。
还有一种更精细的做法是基于重要度的选择性保留。不是简单地按时间顺序淘汰,而是评估每条历史消息的"重要程度"(比如包含用户需求的消息比闲聊更重要),优先保留重要的、淘汰次要的。这种方法效果最好但实现也最复杂,通常需要额外的 LLM 调用来做重要度评估。
1.3 长期记忆:跨会话的持久化知识系统
如果说短期记忆解决的是"当前对话怎么记"的问题,那长期记忆解决的就是"跨对话怎么记、怎么用"的问题。长期记忆让 Agent 可以记住用户的偏好、历史交互的经验教训、领域专有知识等信息,使其表现得更像一个"有积累"的助手,而不是每次对话都从零开始的"失忆者"。
从认知科学的角度,长期记忆又可以细分为两类:显式记忆(Explicit Memory) 和 隐式记忆(Implicit Memory)。显式记忆是可以明确表述的事实和事件,比如"用户 A 喜欢简洁的代码风格"、"上周五的会议决定了下季度的目标";隐式记忆则是内化在模型行为中的模式和技能,对应到 LLM 领域就是通过微调(Fine-tuning)融入模型参数中的知识。
在工程实践中,Agent 的长期记忆主要通过以下几种技术来实现:
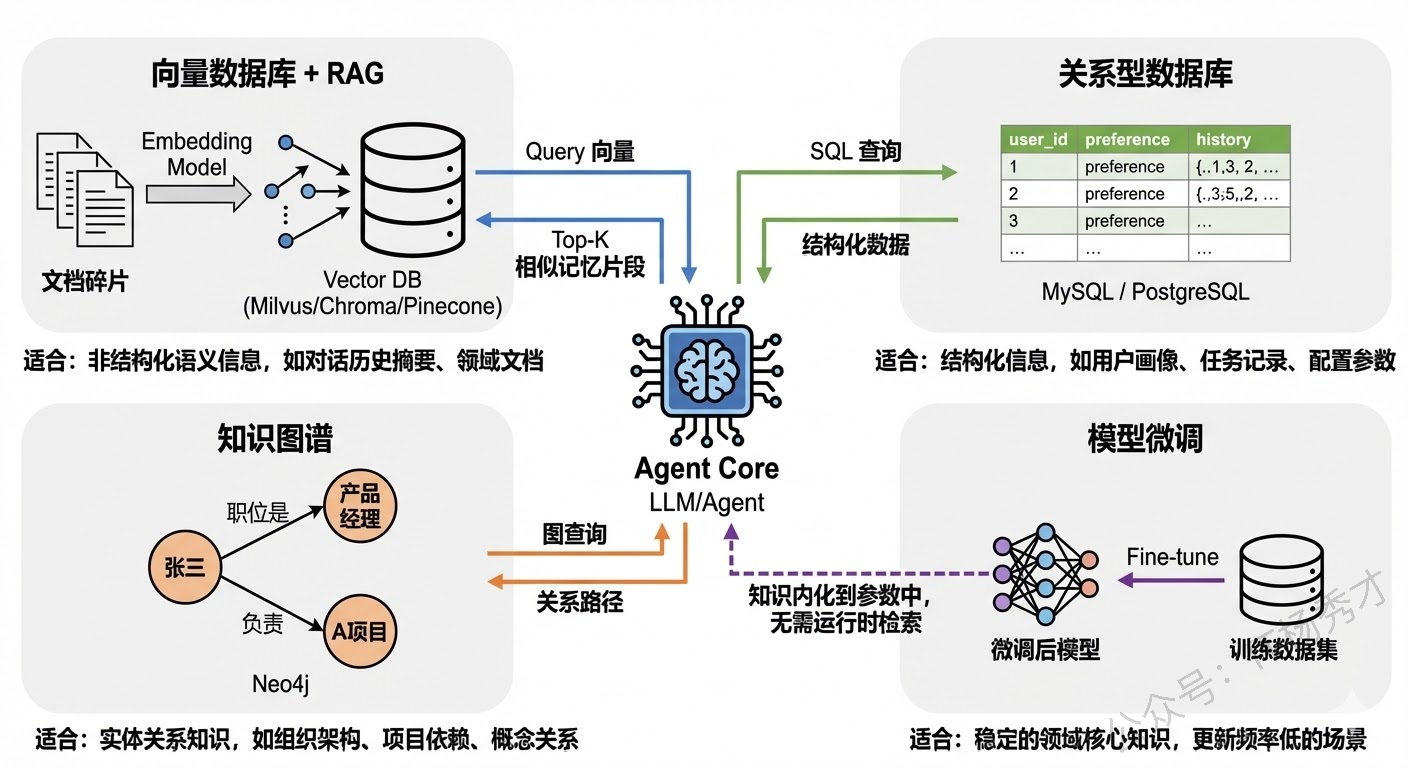
向量数据库 + RAG(检索增强生成) 是目前最主流的长期记忆方案。核心思路是:把需要长期记忆的信息(对话历史摘要、用户画像、领域文档等)通过 Embedding 模型转化为向量,存入向量数据库(如 Milvus、Pinecone、Chroma、Weaviate 等)。当 Agent 需要使用这些记忆时,先把当前问题也转化为向量,然后在向量数据库中做相似度检索,找出最相关的记忆片段,注入到当前的上下文中供 LLM 参考。
这种方案的本质是把长期记忆的"存"和"取"都转化成了向量空间中的操作——存就是 embedding 后写入数据库,取就是语义相似度搜索。它的优势在于检索是语义级别的,即使用户的问法和存储时的原文表述不同,只要语义相近就能检索到。
关系型数据库 / KV 存储 适合存储结构化的记忆信息。比如用户画像(姓名、偏好、历史任务记录等)这类高度结构化的数据,用关系型数据库存储比向量数据库更合适,因为可以精确查询而不是模糊的语义匹配。在实际项目中,往往是向量数据库和关系型数据库配合使用——结构化信息用 MySQL/PostgreSQL 存,非结构化的语义信息用向量数据库存。
知识图谱(Knowledge Graph) 是另一种重要的长期记忆载体,特别适合存储实体之间的关系。比如"张三是产品经理"、"张三负责 A 项目"、"A 项目依赖 B 服务"这类关系型知识,用图结构来存储比纯文本向量化更自然。Agent 在推理时可以通过图查询来获取结构化的关系信息,辅助决策。Neo4j 是最常用的图数据库。
模型微调(Fine-tuning) 则是一种"隐式"的长期记忆方案。通过在特定领域的数据上对模型进行微调,领域知识就被"烧"进了模型参数中,变成了模型的"肌肉记忆"。这种方式的优点是推理时不需要额外的检索步骤,模型直接就能输出相关知识;缺点是更新成本高——每次知识更新都需要重新微调,不像向量数据库那样可以实时增删改。
1.4 记忆的写入、检索与更新机制
光有存储方案还不够,一个完善的记忆系统还需要设计好三个核心机制:什么时候写入记忆、怎么检索记忆、怎么更新和遗忘过期记忆。
写入机制方面,最常见的做法是在每轮对话结束后,由一个专门的"记忆管理模块"来判断当前对话中是否有值得长期保存的信息。比如用户明确表达了某个偏好("我喜欢用 Python")、或者 Agent 完成了一个任务并积累了经验教训,这些就是值得写入长期记忆的信息。写入之前通常需要做一次摘要提炼,把冗长的对话内容压缩成简洁的记忆条目,避免存储大量冗余信息。
检索机制方面,最关键的问题是"检索的时机和精度"。时机上,Agent 在开始处理每个新任务时,都应该先从长期记忆中检索与当前任务相关的历史信息,把它们注入到短期记忆(上下文)中。精度上,除了基于向量相似度的语义检索,还可以结合元数据过滤(比如按时间范围、按用户 ID 过滤)和重排序(Reranking) 来提高检索质量。在实际项目中,一个常见的组合是"向量检索召回 + 交叉编码器重排序"。
更新和遗忘机制也很重要。人的记忆会遗忘,Agent 的记忆也需要。如果长期记忆只增不减,不仅存储成本会越来越高,而且过期的、错误的记忆还会干扰 Agent 的判断。常见的做法包括:为记忆条目设置时间衰减权重(越久远的记忆权重越低)、定期让 LLM 对记忆库做整理和去重、以及当用户明确纠正某个信息时主动更新对应的记忆条目。
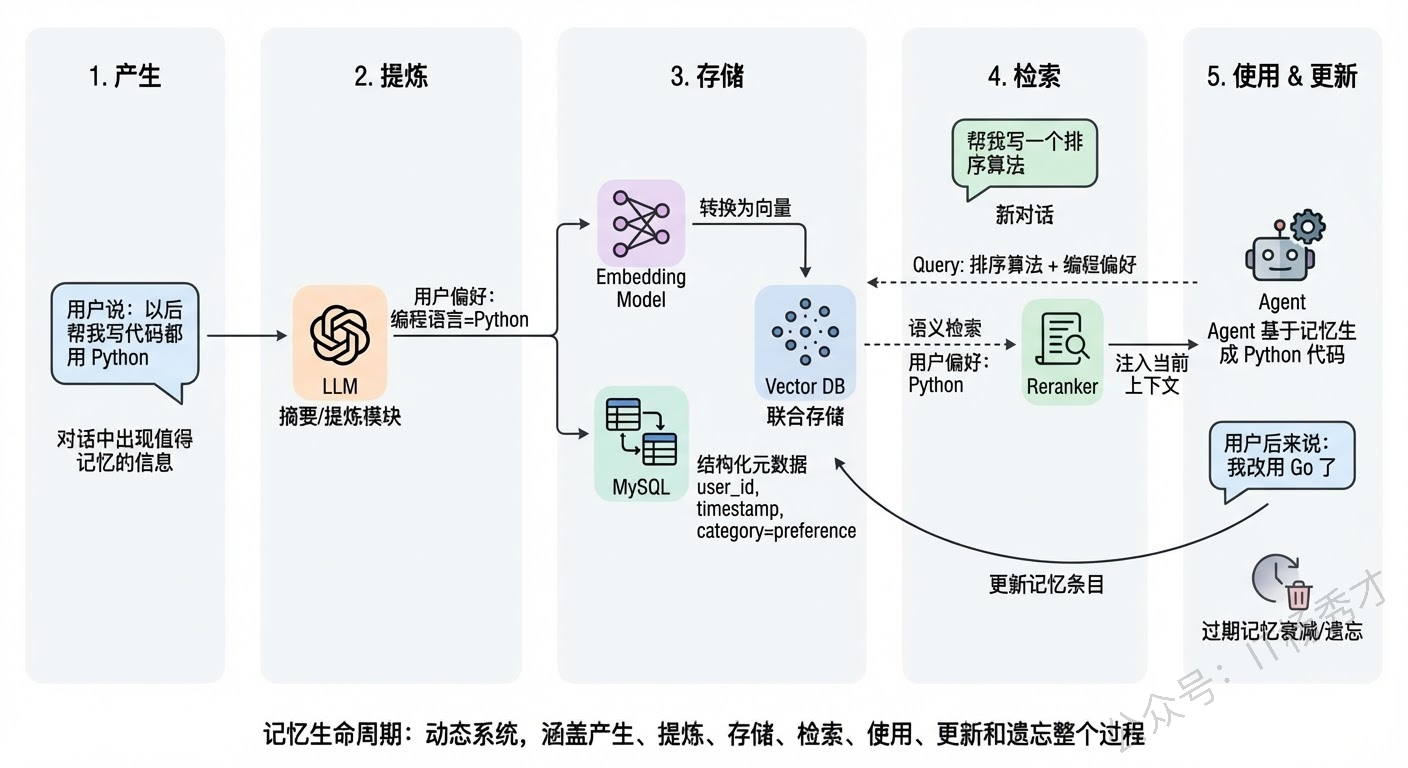
1.5 实际项目中的记忆架构
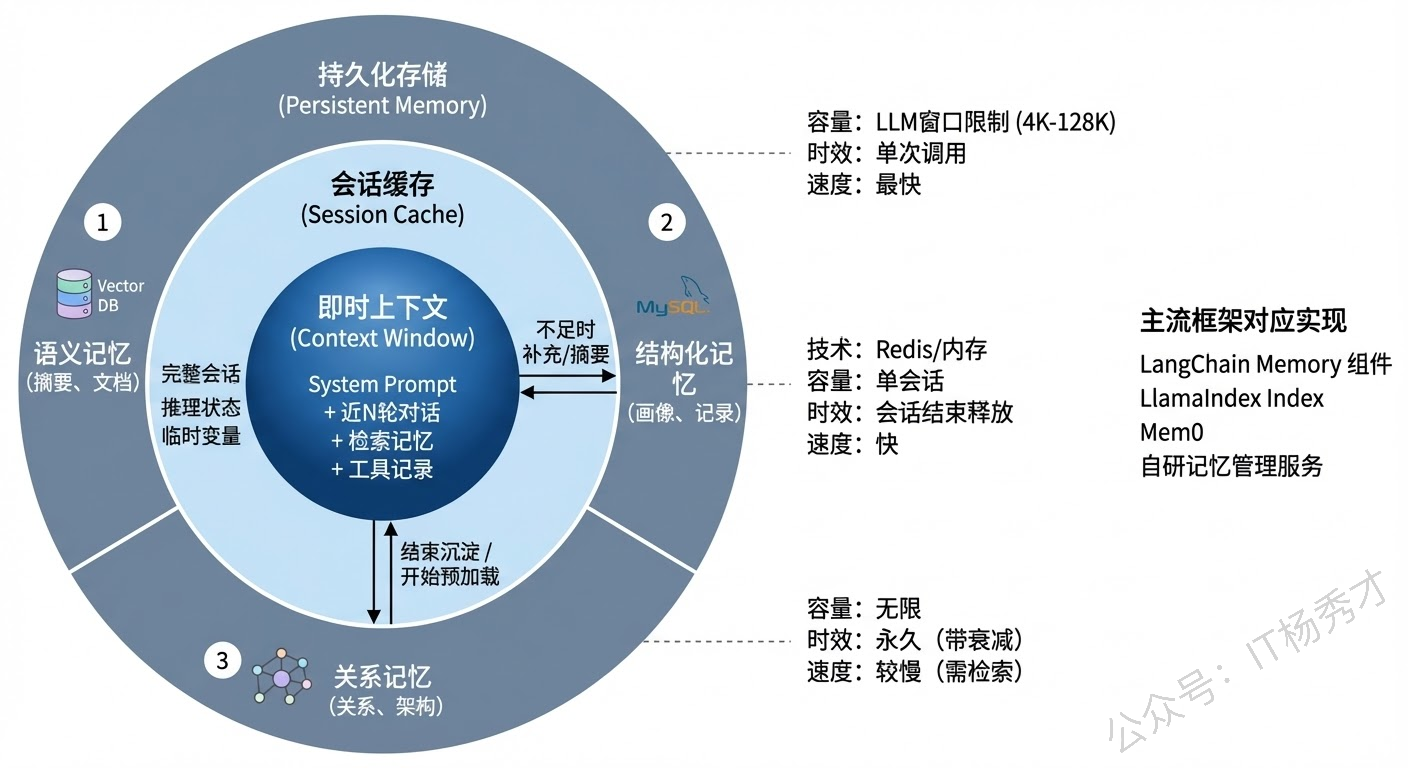
在真实的 Agent 项目中,短期记忆和长期记忆不是孤立运作的,而是协同配合形成一个完整的分层记忆架构。一个典型的设计是这样的:
最内层是即时上下文,也就是当前这轮 LLM 调用的 prompt 内容,包括系统提示词、最近几轮的原始对话、以及从长期记忆中检索注入的相关信息。这是 Agent "当前正在想什么"。
中间层是会话缓存,存储当前整个会话的完整历史(不仅仅是 prompt 中的那几轮),通常用 Redis 这类内存数据库来存。当上下文窗口装不下全部历史时,就从会话缓存中检索或摘要化处理后注入。
最外层是持久化存储,也就是跨会话的长期记忆,用向量数据库 + 关系型数据库 + 知识图谱等方案来承载。当 Agent 需要调用历史经验、用户偏好、领域知识时,就从这一层检索。
信息在三层之间是可以流动的:对话过程中产生的重要信息会从内层向外层"沉淀"(短期→长期),而需要用到的历史知识会从外层向内层"提取"(长期→短期)。这种分层设计既保证了 Agent 的实时响应速度,又提供了近乎无限的记忆容量。
主流框架对这套架构都有很好的支持。LangChain 提供了多种 Memory 组件(ConversationBufferMemory、ConversationSummaryBufferMemory、VectorStoreRetrieverMemory 等),LlamaIndex 则更侧重于通过索引结构来组织长期记忆。Mem0 是一个专门做 Agent 记忆管理的开源项目,它提供了开箱即用的记忆存储、检索、更新和遗忘机制。
2. 参考回答
Agent 的记忆系统可以类比人类记忆来理解,分为短期记忆和长期记忆两个层面。
短期记忆本质上就是 LLM 的 Context Window,它承载当前对话的上下文信息,核心挑战是窗口容量有限。工程上主要有几种管理策略:最基础的是滑动窗口截断,但容易丢失早期关键信息;更好的方案是对话摘要压缩,用 LLM 把较早的对话历史压缩成摘要,LangChain 的 ConversationSummaryBufferMemory 就是典型实现,它对早期对话做摘要、近期对话保留原文,兼顾了信息保留和 token 控制,这也是实际项目中最常用的方案。
长期记忆则是跨会话的持久化知识系统,需要借助外部存储来实现。目前最主流的方案是向量数据库 + RAG,把对话摘要、用户偏好、领域知识等通过 Embedding 向量化后存入 Milvus、Chroma 这类向量数据库,Agent 处理新任务时通过语义检索把相关记忆调出来注入上下文。对于结构化信息如用户画像、任务记录,用关系型数据库更合适,实际中往往是向量库和关系库配合使用。如果涉及复杂的实体关系,比如组织架构、项目依赖关系,还可以引入知识图谱用 Neo4j 来存储。除了存储方案,记忆的完整生命周期管理也很关键——什么时候写入、怎么检索、怎么更新遗忘。写入时需要先做摘要提炼避免冗余,检索时可以结合语义搜索加元数据过滤再加 Reranker 重排来保证精度,同时还需要时间衰减和定期整理机制来淘汰过期记忆。
整体架构上,我在实际项目中采用的是三层分层设计:最内层是即时上下文窗口、中间层是 Redis 做的会话缓存、最外层是持久化存储,信息在三层之间双向流动——重要信息从内向外沉淀存储,需要时从外向内检索注入,这样既保证了实时响应速度,又实现了近乎无限的记忆容量。