DevSupport AI
面向 API 开放平台的多 Agent 智能客服系统 —— 一个拆得开、跑得起、能写进简历的「工程级」大模型应用。

DevSupport AI 是一个精心打磨的大模型 AI Agent 实战项目,定位很清晰——面向 API 开放平台的多 Agent 智能客服系统。
先做个区分:现在打着智能客服旗号的项目很多,但大多拆开来看,无非是一段 Prompt 加几轮大模型调用,多问几轮就露怯。DevSupport AI 走的是相反的路线,它把一个客服真正该具备的能力一项不落地补齐了——能听懂开发者的技术问题、能检索文档、能查调用日志、能解释账单、该脱敏的地方一处不漏,遇到自己解决不了的,还会把上下文整理完整、自动创建工单转交人工接手。
底层选用的是大模型应用里最主流的一套:Python + FastAPI + LangGraph,配合 Milvus、MySQL、Redis 和通义千问 DashScope。从需求怎么拆、架构怎么定、代码怎么落地,到怎么写进简历、面试官追问时如何应对,我用整整 31 篇教程完整讲了一遍,每一行代码都对照仓库里的真实实现,没有一处是凭空编造。
它的工程化程度也不是空谈,是有数据支撑的:冷启动 P95 从 48.6 秒优化到 6.8 秒;热点问题命中缓存只需 0.38 秒,且零 Token 开销;已知错误码直接查表,比走完整 RAG 快了将近 80 倍;15 道标准评测题里,意图、实体、引用、转人工、澄清、脱敏六项指标全部满分、Badcase 为 0。这些数字,放到面试桌上每一个都拿得出手。
这个项目是做什么的
简单说,整套系统的核心就一件事:开发者在对接你家 API 时遇到问题——报错、被限流、账单看不懂、文档查不到——直接发起提问,AI 自行检索文档、查阅日志、核对账单,给出结论和下一步的修改方法;确实解决不了的,自动整理好上下文创建工单,转交人工处理。
为什么这个场景适合用多 Agent 来做?因为 API 客服类问题有个共同特征:技术性强、高度依赖上下文、高频重复但每次细节又各不相同。纯靠人工应对很吃力——首次响应要排队,客服得反复确认 request_id、接口名、错误码,定位一个问题还要在网关日志、套餐权限、接口配置、历史工单之间来回查,客服处理不了就要拉研发介入,研发于是被频繁打断、迭代效率下降。DevSupport AI 把这些散落各处的系统接到一起,能自助的当场自助,自助不了的也不必让人工从零开始排查。
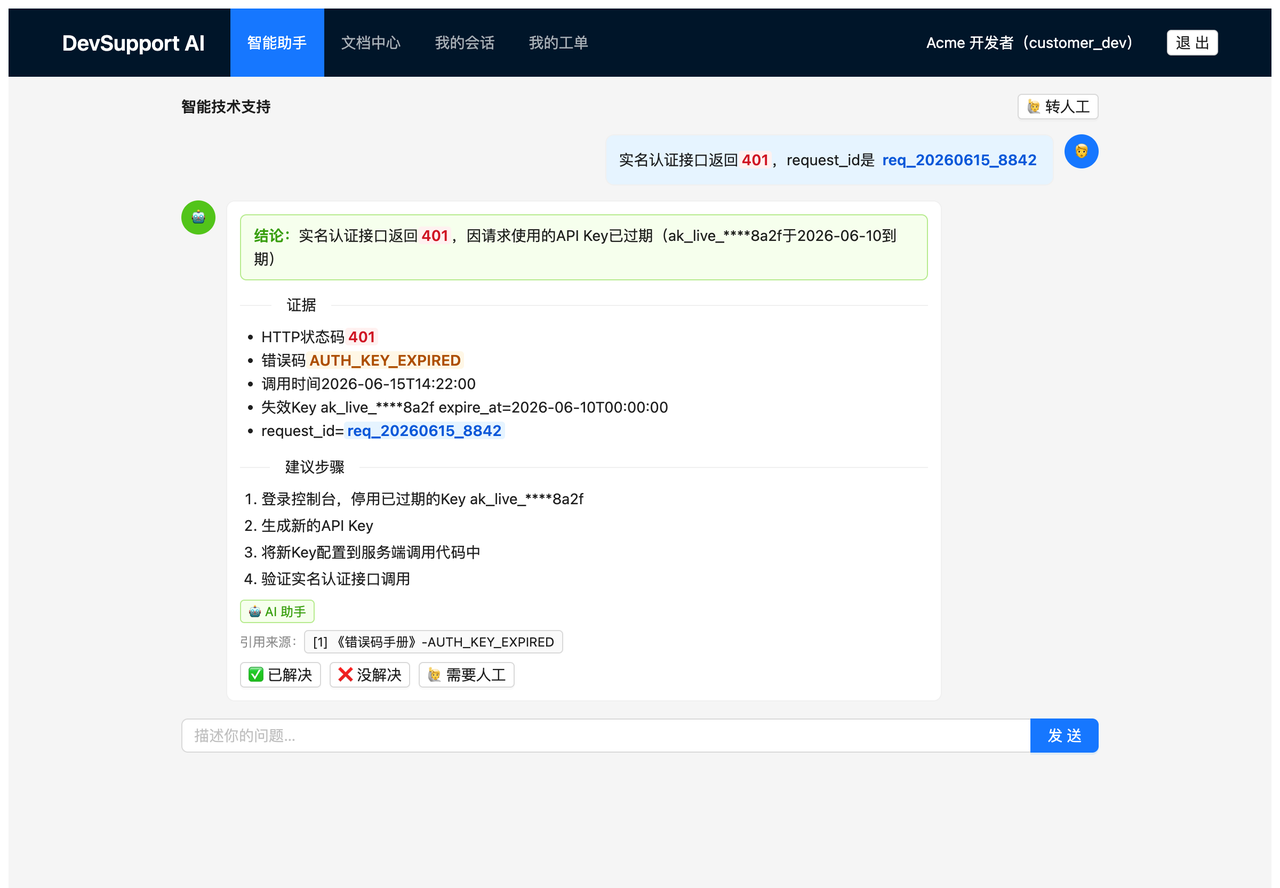
下面是真实运行的效果。开发者反馈「实名认证接口一直返回 401」,AI 直接给出一张结构化卡片——结论、证据、修复步骤、文档出处分得清清楚楚,注意证据里的那把 API Key,已经被脱敏为 ak_live_****8a2f:
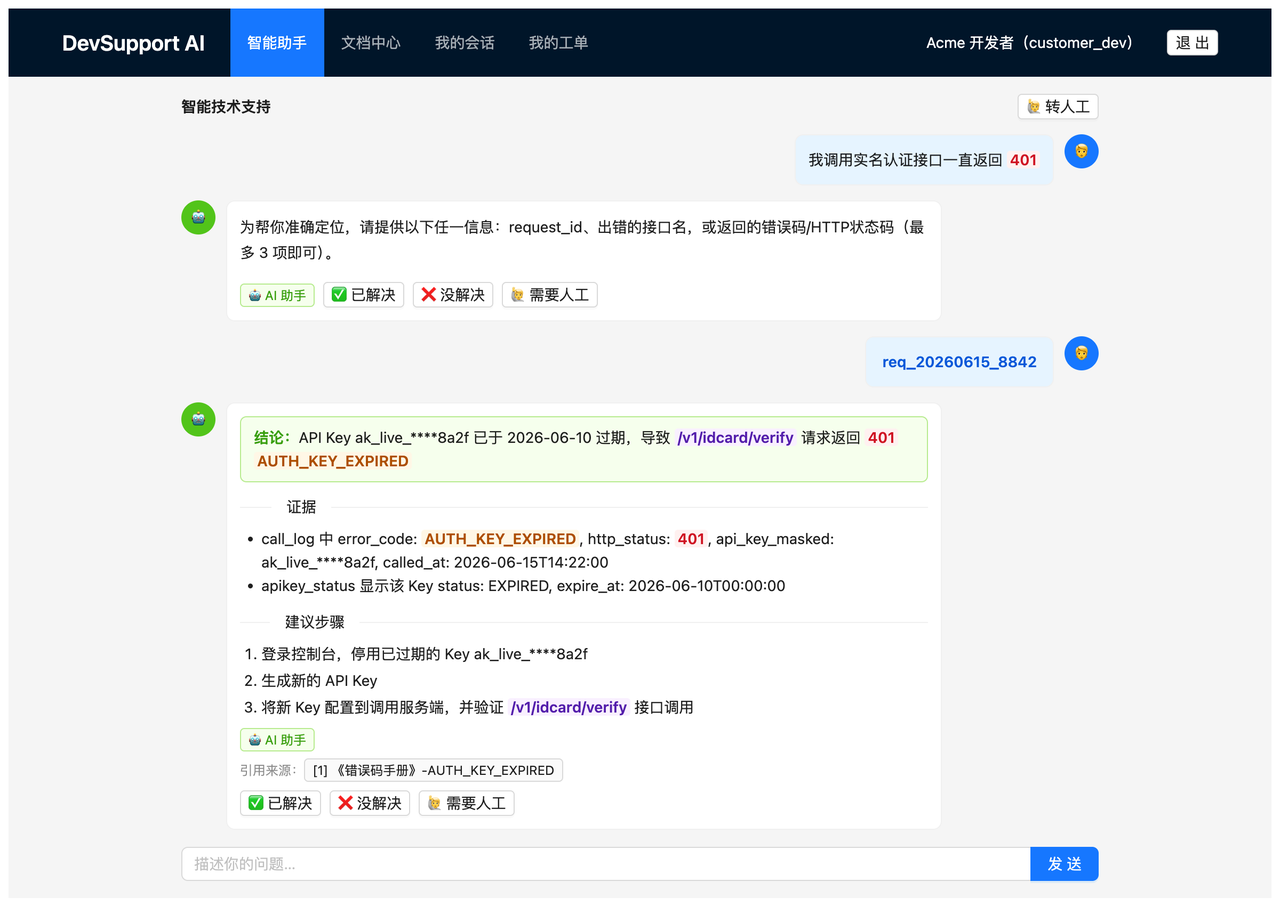
遇到信息不全的提问,它不会强行给出一个答案搪塞,而是先把缺失的关键信息确认清楚——request_id、接口名、错误码——拿到之后再下结论。更省心的是,已经问到的实体会被记入这轮会话,下一句不必重复提供:
项目技术栈
技术选型上没有追求新奇,都围绕主流、能落地、招聘方认可来选。概括起来就是:Python 后端那套成熟工具 + 大模型应用最常用的编排与检索组件,上手不陌生,学完即用。
| 技术层级 | 选型 | 一句话说明 |
|---|---|---|
| 开发语言 | Python 3.11 | 大模型应用生态最厚的语言,库最全 |
| Web 框架 | FastAPI + Uvicorn | 异步高性能,SSE 流式输出依赖 sse-starlette |
| Agent 编排 | LangGraph + langchain-core | 用 StateGraph 把多 Agent 串成 DAG,本项目的核心骨架 |
| 大模型 / Embedding / Rerank | 通义千问 DashScope(OpenAI 兼容) | 一个 Key 跑通对话、text-embedding-v3(1024 维)、gte-rerank-v2 |
| 向量库 | Milvus(pymilvus 2.4) | 存放知识切片,做向量语义检索 |
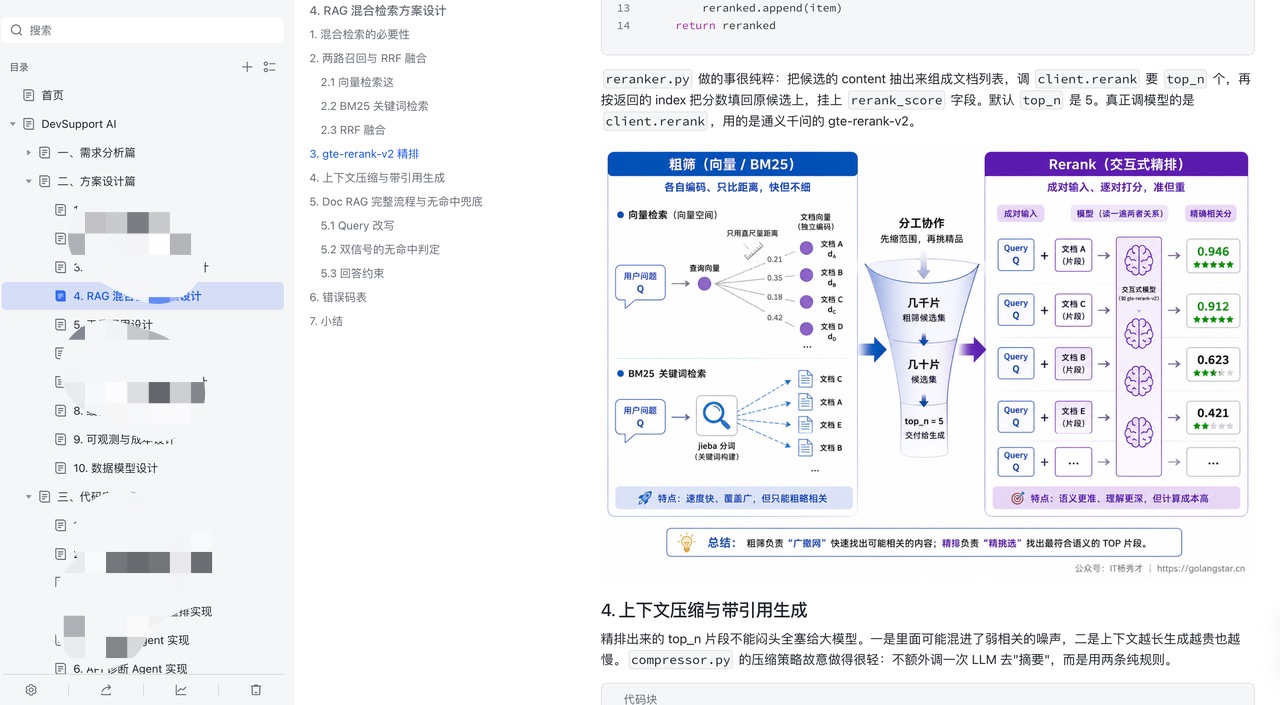
| 关键词检索 | rank-bm25 + jieba 分词 | 与向量检索两路并行召回,再做 RRF 融合 |
| 关系库 | MySQL 8(SQLAlchemy 2.0 + aiomysql) | 业务数据、会话、工单、trace 全部落库 |
| 缓存 / 会话 | Redis 5 | 短期记忆、语义缓存、路由缓存 |
| 认证 | JWT(python-jose + bcrypt) | 登录鉴权 + 多租户隔离 |
| 健壮性 | tenacity + httpx | 工具调用的超时重试、外部请求 |
| 前端 | React 18 + TypeScript + Vite | 现代前端工程,构建快 |
| 前端 UI / 可视化 | Ant Design 5 + React Flow + react-markdown | 组件库打底,React Flow 绘制 Agent 链路,markdown 渲染回复 |
| 部署 | Docker Compose | 一条命令拉起 MySQL / Redis / Milvus |
| 测试 / 压测 | pytest + locust | 单元测试加并发压测,性能数据由此跑出 |
每一项在教程里都有对应落点——为什么选它、怎么接入、踩过哪些坑,而不是只甩出一个名词。
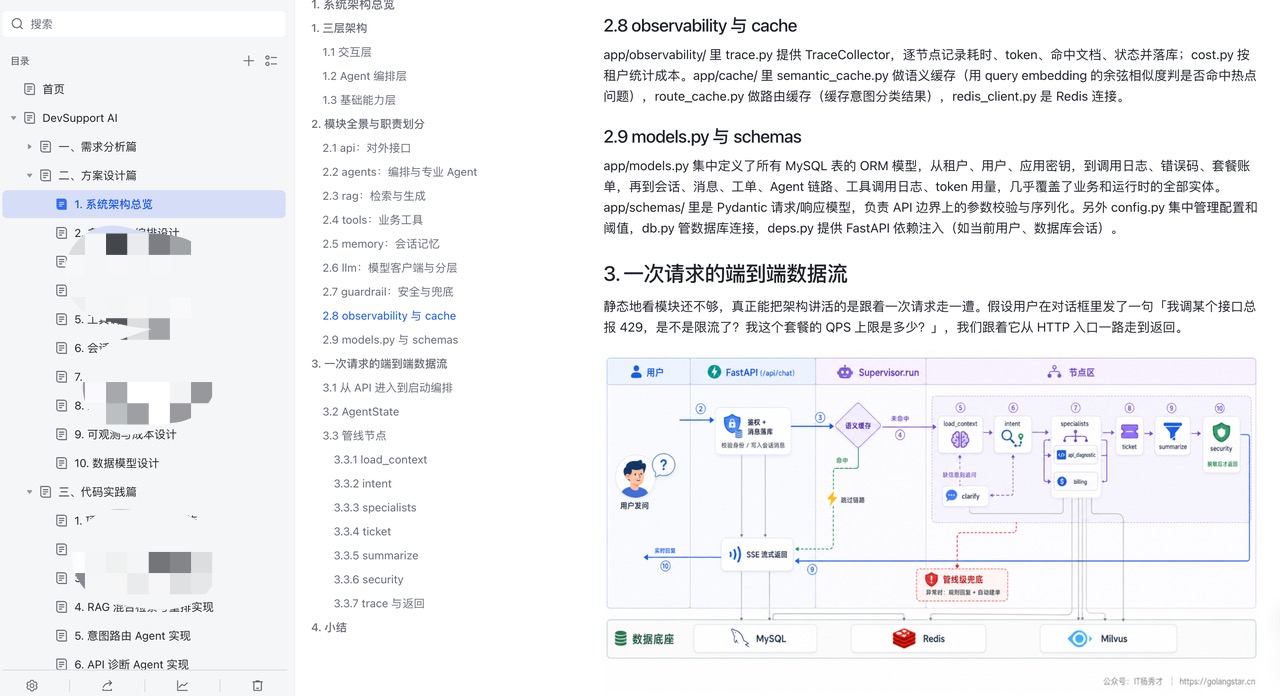
系统架构:三层结构,七个 Agent
一个 AI 项目扎不扎实,把架构拆开就能看出来——不少项目拆开后只剩一个转发壳。DevSupport AI 经得起拆:中间一个 Supervisor 统一调度,下面六个各司其职的专职 Agent 负责干活,旁边还挂着 RAG 检索、短长两层记忆、三道脱敏关卡、多级兜底和全链路追踪,每一块都配有设计文档和能跑的代码。
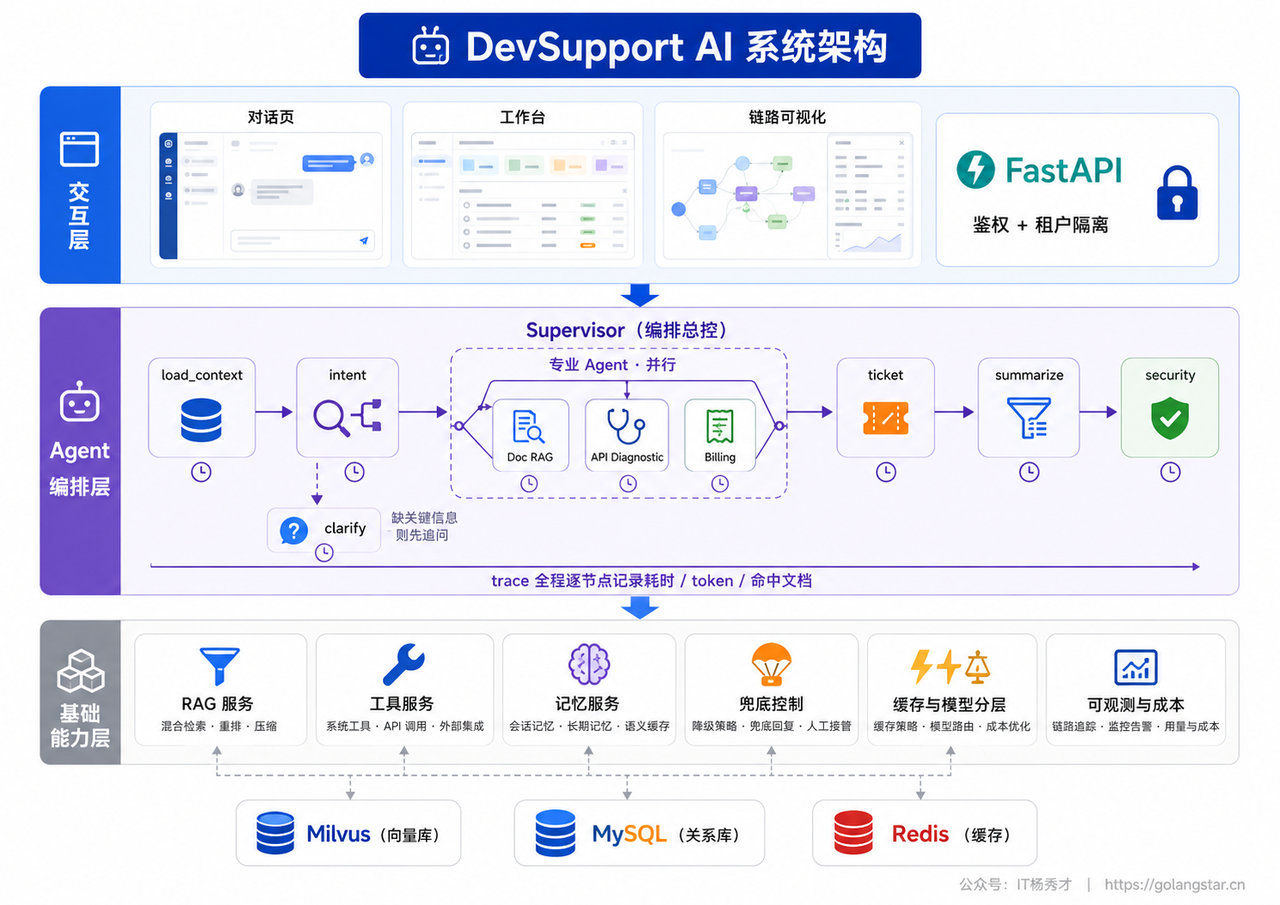
整体自上而下分三层,职责清晰、单向依赖:
- 交互层:统一对外提供接口和流式输出,承担鉴权、租户隔离和请求落库,客户侧对话页和内部客服工作台都走这里。
- 编排层(核心):消息进来先做意图识别和实体抽取,再由 Supervisor 把多个专业 Agent 按一条固定管线串起来协同——诊断、账单、文档问答并行处理,安全审查固定收尾,保证任何回复都不会绕过脱敏。每个节点职责单一、边界清晰,单独拆出来都能测试。
- 基础能力层:RAG 检索、工具调用、会话记忆、安全脱敏与多级兜底、缓存与模型分层、可观测与成本统计等一组互不依赖的能力模块,按需被编排层调用。
三层单向依赖带来的好处是每一层都能独立演进:换前端不影响编排逻辑,加一个新的专业 Agent 不用改接口层,调整检索策略也波及不到上层。至于每一层具体怎么落地、管线怎么设计、模块怎么拆,配套教程里都有完整的设计文档和对应代码。
十大核心技术亮点
下面这十个点,任意挑出两三个,就能在简历上写出一段有分量的项目经历——而且每一个都是面试官会顺势往深处追问的方向。这里先说清每一点解决了什么问题、价值在哪,至于具体怎么实现、怎么一步步落地,都在配套教程里讲透了,这也正是它与套壳项目的分水岭。

一、多 Agent 编排。 不是单靠一句 Prompt 走天下,而是用主流编排框架把意图识别、并行诊断、建单、汇总、安全审查等节点串成一条有向管线,每个 Agent 职责单一、边界清晰、可独立测试。
二、意图路由加实体记忆。 消息进来先判断意图、抽取关键实体,再按规则推荐到对应的专业 Agent;已经问到的信息记入本轮会话,下一句不必重复提供。
三、RAG 混合检索加重排。 只靠向量检索是不够的。这里把向量语义检索和关键词检索两路并行召回、融合、精排、压缩,最后带引用生成,无命中时如实兜底——不糊弄、不编造。
四、工具调用中心。 工具统一注册管理、带超时重试、调用日志脱敏后再落库,像重置 API Key 这类高危操作根本不开放给 AI,只能走人工或后台。
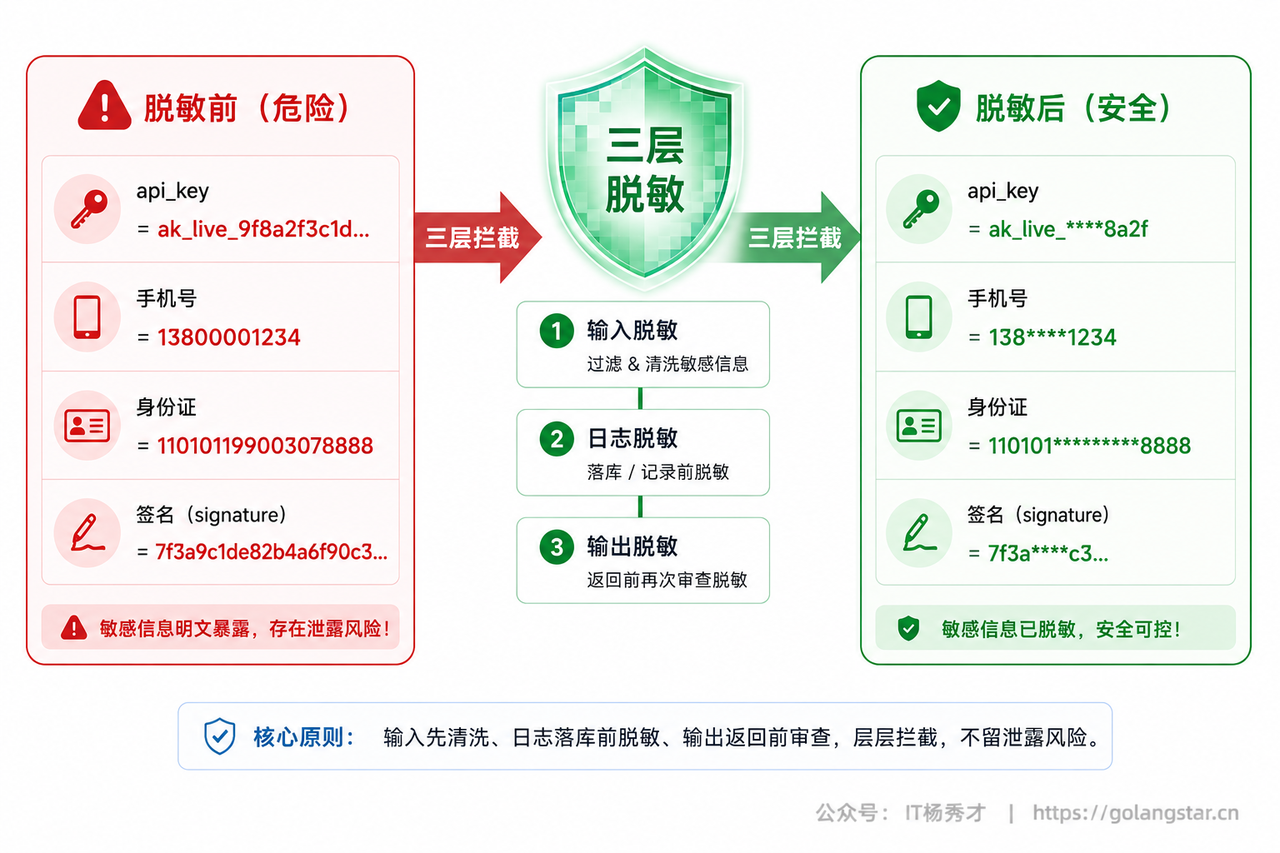
五、三层安全脱敏。 在用户输入、工具结果与日志、最终输出三处各设一道关,API Key、Secret、Token、手机号、邮箱、身份证、签名、银行卡等敏感信息全程覆盖。
六、多级兜底。 这个系统不会裸奔:单个 Agent 异常就地隔离、不连累整体;文档未命中就明确告知不确定、转人工建单;整条管线异常就退到规则回复加自动建单。
七、缓存加模型分层。 语义缓存让重复或相似的问题0.38 秒返回、零 Token 开销;轻任务用小模型、重任务用大模型,成本和延迟一起往下压。
八、全链路可观测加成本核算。 每个请求逐节点记录耗时、token、命中了哪几篇文档、处于什么状态,前端再把整条 Agent 链路可视化绘制出来,还能按租户把 Token 成本核算清楚,瓶颈在哪一目了然。
九、评估加压测。 Agent 和 RAG 做完不评估,等于盲飞。这里有标准评估集,意图、实体、引用、转人工、澄清、脱敏逐项打分(实测六项全满分、Badcase 为 0),还配了并发压测脚本和优化前后对照,一切用数据说话。
十、工程化齐全。 一条命令拉起全部依赖、一条命令完成建表灌数据,全程只需一个 API Key 即可运行,JWT 认证、多租户隔离、流式输出一应俱全。
多 Agent 如何协同
只说"多 Agent"比较抽象,看一个复合问题就清楚了。开发者提出「今天下午一堆 429,是不是你们服务挂了?」——这个问题背后其实裹着好几个原因。Supervisor 会并行调度:让 API 诊断 Agent 去查最近的调用量、账单 Agent 去核当前套餐的 QPS、文档 Agent 去检索限流和重试策略,最后再把三方结论汇成一段回复。在内部的客服工作台里,这整条 Agent 链路被 React Flow 一笔一笔绘制了出来,哪个节点花了多少毫秒、消耗了多少 token,看得清清楚楚:
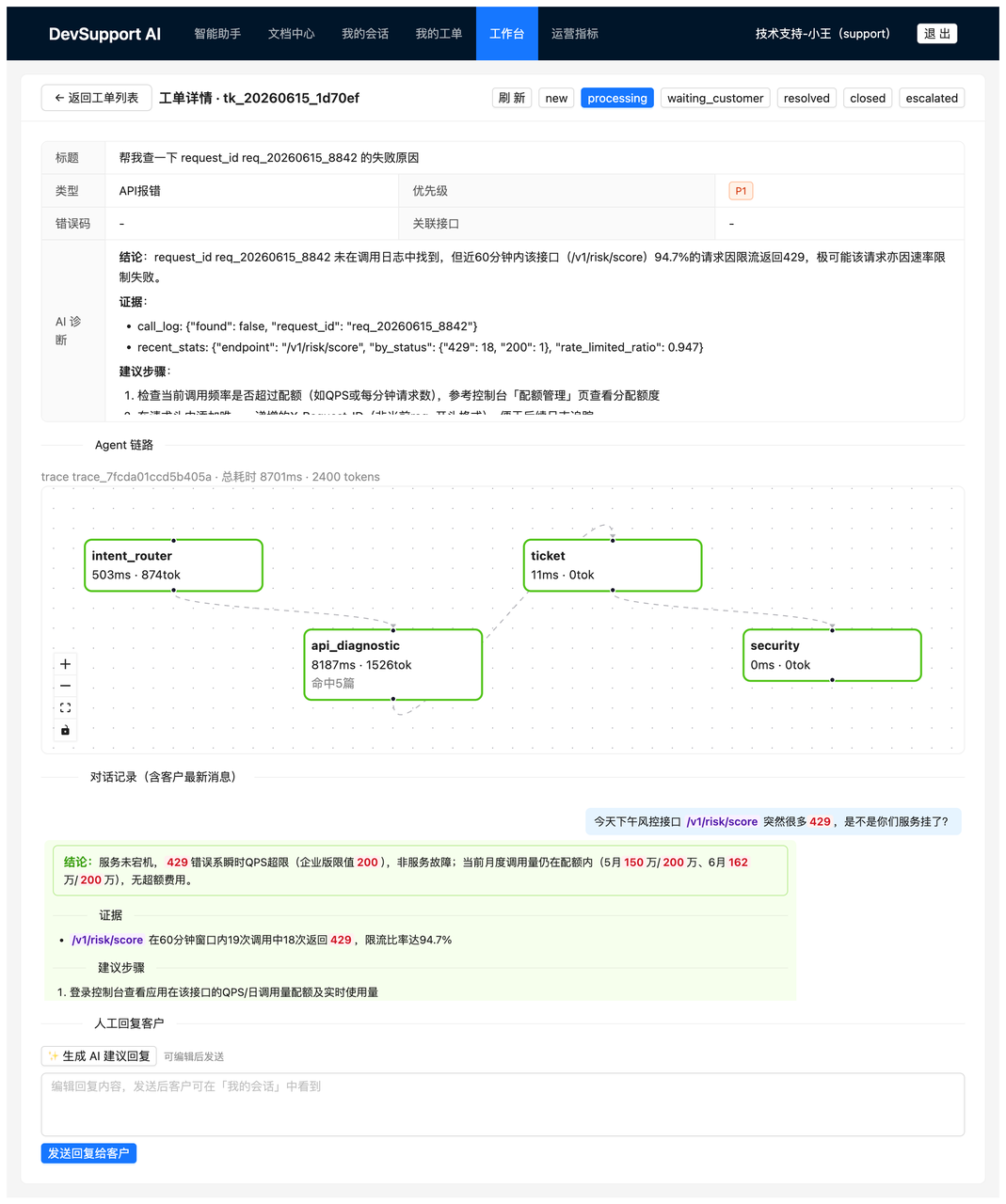
这条链路图,是整个项目最能体现工程深度的部分。客服坐席点开一张工单,不必从头读一遍对话,AI 的意图判断、拿到的证据、最终结论、每个 Agent 各耗时多少,一屏尽收。它同时也是性能优化的入口——每个阶段都单独计时:
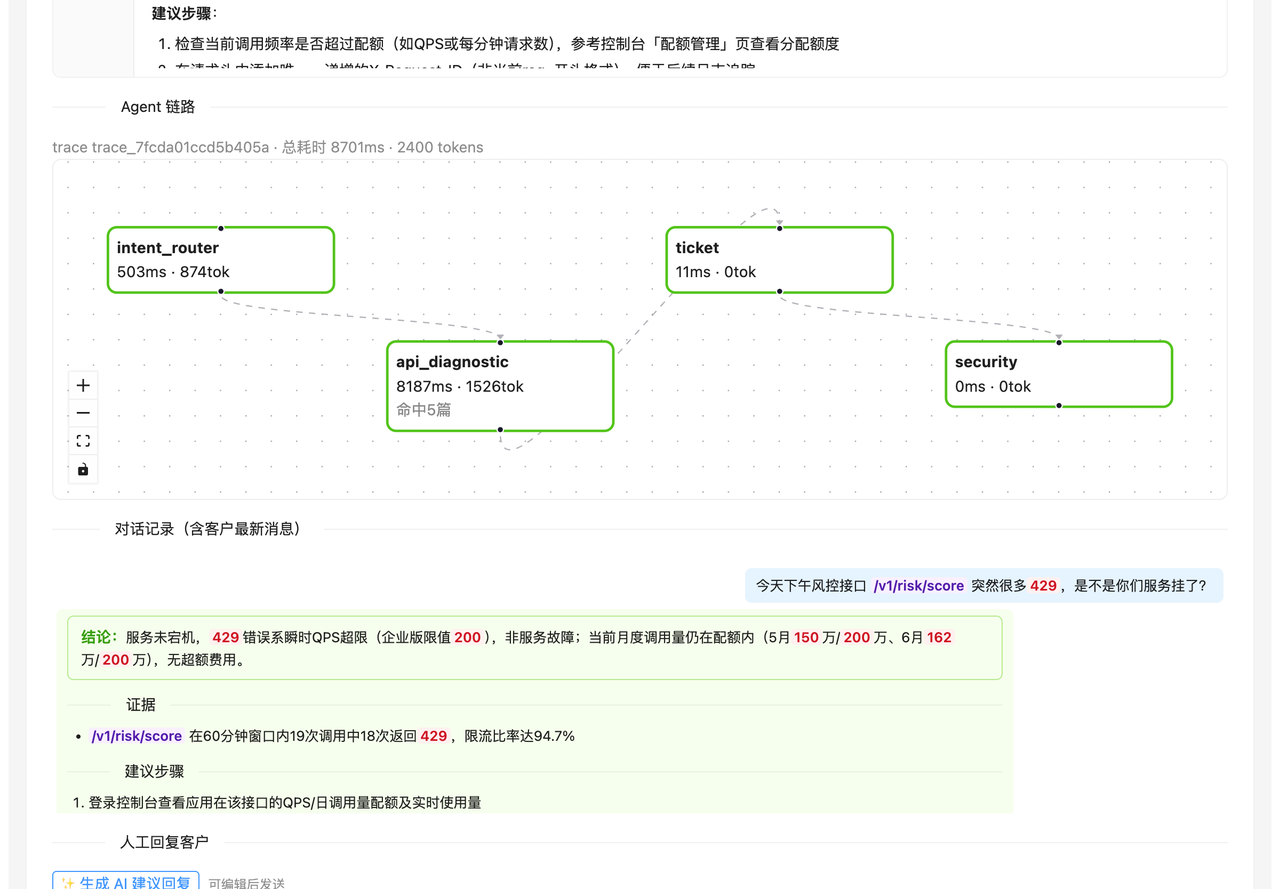
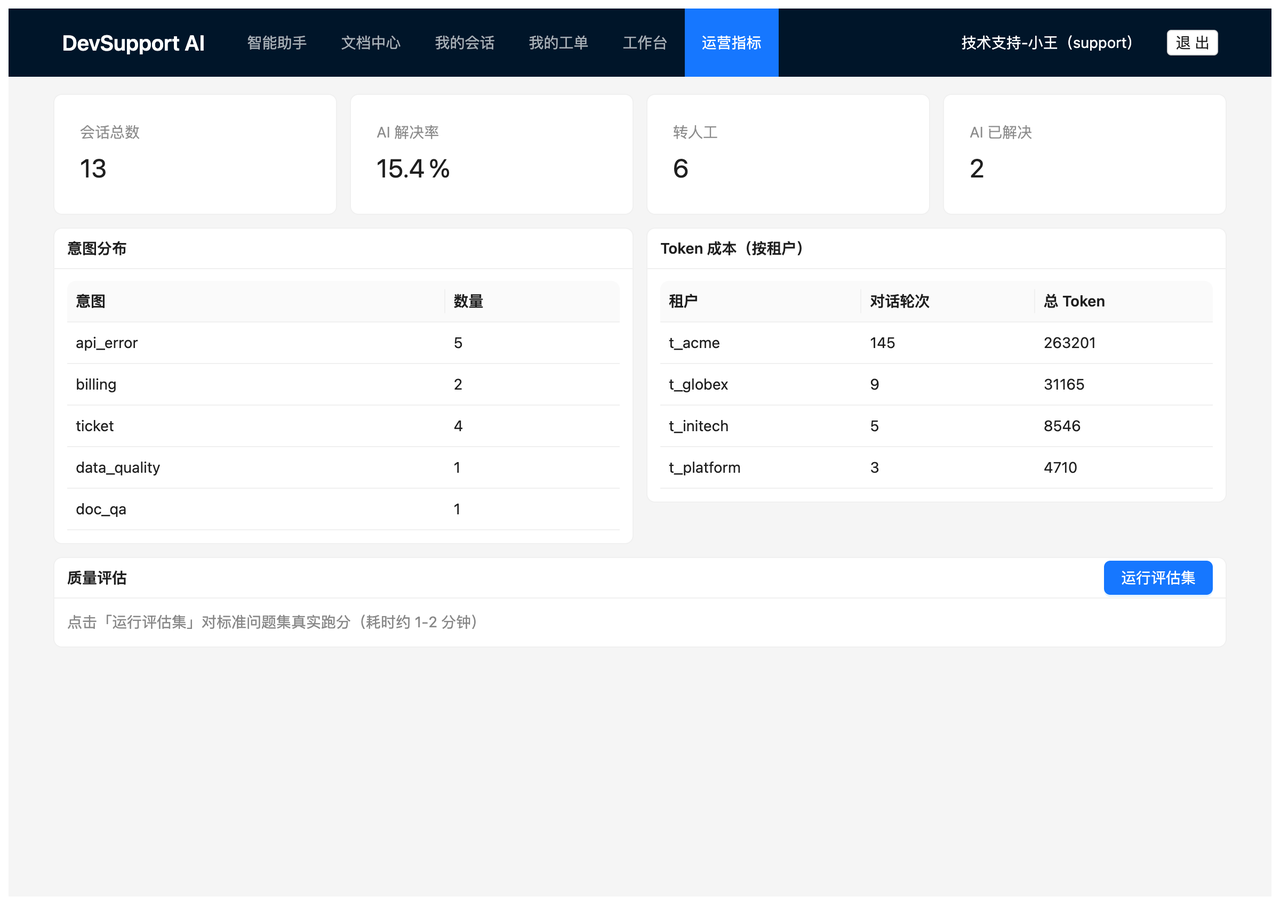
至于效果好不好,不靠空说。运营指标页摆着真实的会话总数、AI 解决率、意图分布、各租户的 Token 花销,还能一键拉起标准评估集当场跑分:
性能优化:从 48 秒到 6 秒
这个项目我没有停在"能跑就行",而是认真做了一轮性能优化,并把优化前后的真实压测数据原样记录了下来。这部分内容拿去面试很有分量——大多数候选人的 AI 项目只做到调通,讲不出"我优化了什么、提升了多少、为什么这么改"。

几个关键数据(全部基于真实服务 DashScope + Milvus + MySQL + Redis 实测):
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 冷启动 P95 | 48.58s | 6.83s | ~7x |
| 吞吐 | 0.18 req/s | 0.75 req/s | ~4x |
| 语义缓存命中 | 9.92s / 1491 Token | 0.38s / 0 Token | 26x · 0 成本 |
| 错误码文档支撑 | 全程 RAG 0.74s | DB 直取 0.010s | 78x |
这背后是八项手段叠加的结果:语义缓存、路由缓存、错误码热路径直取、Agent 内并行(asyncio.gather)、链路去冗余(单 Agent 场景省掉一次 summarize)、模型分层、上下文压缩、多 Agent 并行。每一项都能说清"原来瓶颈在哪、改了什么、提升多少"——这正是把一个 AI 项目从"调通"推进到"调优"的关键一步。
配套教程:31 篇,从需求到面试
项目不是只丢给你一堆代码自己摸索。它配套了 4 大篇章、31 篇深度教程,从需求一路覆盖到简历面试,代码全部忠于真实实现,绝不杜撰。
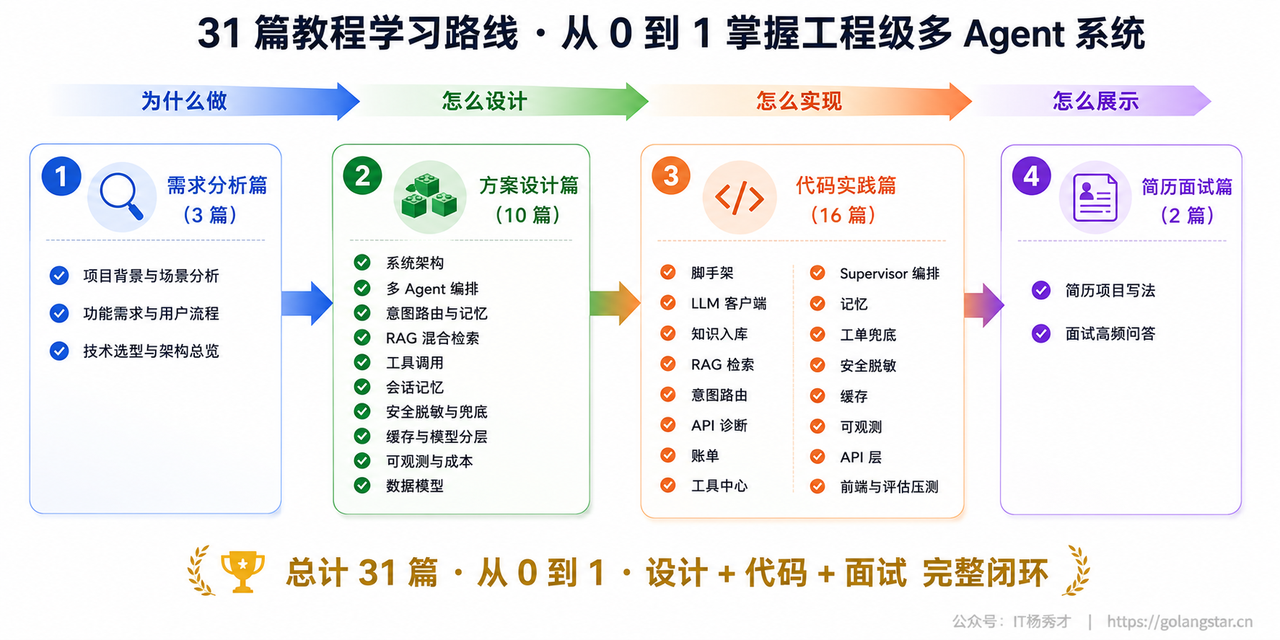
第一篇章:需求分析(3 篇),讲为什么做:API 客服到底难在哪、用户是谁、这个场景为什么适配多 Agent 加 RAG(附一张业务特征对技术方案的对照表),最后落到技术选型和架构总览。
第二篇章:方案设计(10 篇),讲怎么设计:系统架构、多 Agent 编排、意图路由与记忆、RAG 混合检索、工具调用、会话记忆、安全脱敏与多级兜底、缓存与模型分层、可观测与成本、数据模型——一个模块一篇,每篇都把"为什么这么设计、当时权衡了什么"讲透。
第三篇章:代码实践(16 篇),讲怎么落地:从脚手架起步,一篇对应一个能独立运行的阶段,手把手带你把每个功能亲手实现出来。
第四篇章:简历面试(2 篇),讲怎么展示:一篇是项目简历的两种写法(三段式加精简版模板),一篇是面试高频问答——为什么多 Agent、RAG 为什么混合检索、RRF 和 Rerank 的原理、三层脱敏、多级兜底、Badcase 怎么定位,逐题给出参考答案。
部分项目文档截图:
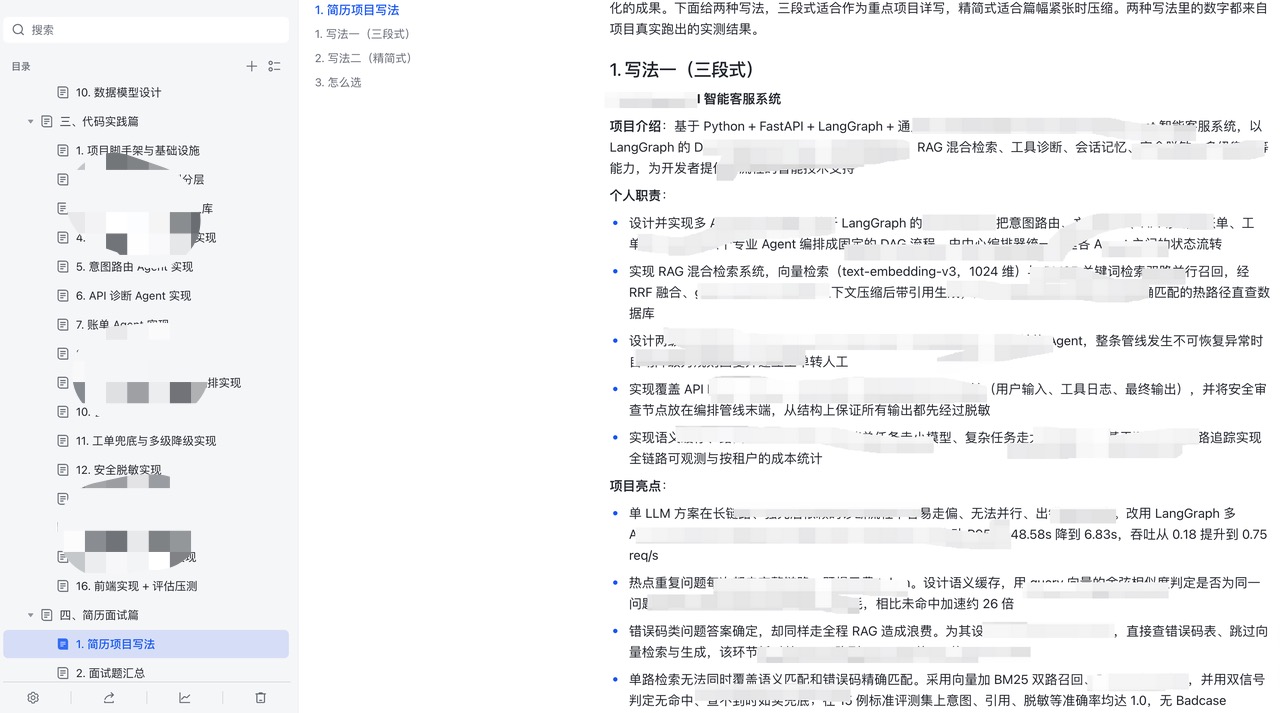
这个项目适合谁

正在准备面试、简历偏空的求职者:这十个亮点任选两三个,就够写一段有料的项目经历,而且每一条都踩在面试高频考点上,后面还附了简历写法和面试题及参考答案。
想转向 AI 方向的后端开发者:项目用的就是 Python + FastAPI + LangGraph,大模型应用最主流、最贴近真实生产和招聘要求的一套,学完直接能上手。
理论看了不少、却从没整体落地过的 AI 学习者:Agent、RAG、脱敏、兜底各自都懂一点,但串不成一个系统——这套教程正好从需求、设计、代码到面试一条龙,每个模块都配有设计文档、代码实现和面试话术。
要做 B 端、企业级 AI 应用的工程师:这个项目的"生产味"对你最实用:多级兜底、安全脱敏、租户隔离、全链路可观测、性能压测调优,这些能力拆出来就能迁移进你自己的业务。
你能收获什么
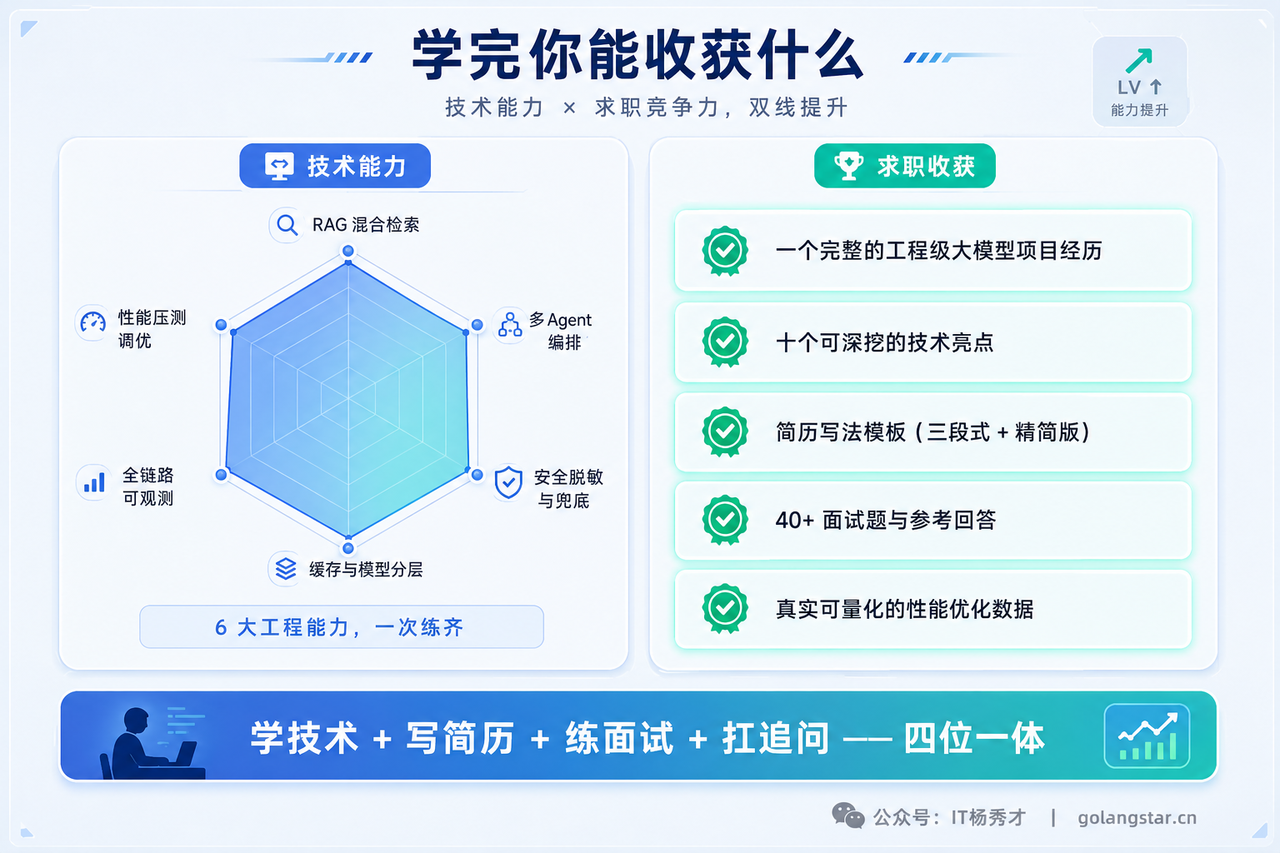
一句话:学技术、写简历、练面试、扛追问,四件事一次到位。你得到的不只是一份能跑的代码,而是一段写得进简历、面试时讲得透、还经得住面试官层层深问的完整工程级项目经历。
如何获取
299 元,整套源码加 31 篇深度教程一次到手。【AI模拟面试官】、【DevSupport AI】两个项目打包价只要499。购买「DevSupport AI 项目」后,你将解锁这些权益:
✅ 全套项目文档资料,永久可看
✅ 完整项目源码(Python + FastAPI + LangGraph,真实可跑)
✅ 文档答疑 + 专属交流群(飞书 + 微信)
✅ 现成 2 种简历写法(项目亮点和难点全都有),直接拿去面试
✅ 项目 50+ 相关面试题(全都是项目高频面试题,后续还会持续增加)
✅ 真实可量化的性能优化与压测数据,面试硬核加分
对项目感兴趣,可以扫描以下二维码添加秀才微信咨询,备注『项目咨询』。

更多学习教程请访问学习网站:https://golangstar.cn