什么是大语言模型
1. 大语言模型基础定义
LLM 全称 Large Language Model,即大语言模型,是一种用大量数据训练的深度学习模型,给模型一些输入,它可以预测并返回相应的数据。
和以往的 NLP 自然语言模型有差异的是,LLM 的训练数据和参数量都非常大,所以 LLM 能完成通用型的任务,不需要专门针对某个领域单独训练。
以 GPT- 3 为例,GPT- 3 的训练数据由多个部分组成,涵盖了书籍、新闻、论文、维基百科、社交媒体等几乎人类所有的高质量文本近 3000 亿个文本单位,分布如下:
| Dataset | Quantity | Weight in Training mix | Epochs elapsed when Training for 300B tokens |
| Common Crawl(filtered) | 410 billion | 60% | 0.44 |
| WebText2 | 19 billion | 22% | 2.9 |
| Books1 | 12 billion | 8% | 1.9 |
| Books2 | 55 billion | 8% | 0.43 |
| Wikipedia | 5 billion | 3% | 3.4 |
CommonCrawl(网络爬虫公开数据集):占比 $60%$
WebText2(Reddit论坛的网页文本):占比 $22%$
Books1,Books2(互联网书籍语料库):占比 $16%$
Wikipedia(整个英文维基百科知识库):占比 $3%$
CommonCrawl(网络爬虫公开数据集):占比 $60%$
WebText2(Reddit论坛的网页文本):占比 $22%$
Books1,Books2(互联网书籍语料库):占比 $16%$
Wikipedia(整个英文维基百科知识库):占比 $3%$ 数据引用自:https://arxiv.org/abs/2005.14165
除了训练数据大,大模型的参数也非常大,以OpenAI历代公开大模型参数量为例。GPT- 1的参数为1.17亿,虽然参数看起来不大,但是对比GPT- 1之前的语言模型仍增长了数十倍。而GPT- 2的参数量为15亿,GPT- 3的参数量为1750亿,未开源的GPT- 4参数预估量更是达到了惊人的上万亿。
在大训练数据量和大参数的基础下,大模型能够流畅地完成通用型的任务,而不是像NLP自然语言模型一样,针对某个特定领域时需要单独的数据训练才可以实现。
生成任务:基于特定的输入(例如关键词、短语或描述性的语句)生成全新的内容或想法。这可能包括写作(例如,文章、短篇故事或诗歌)艺术品生成、音乐创作等。
分类任务:涉及确定给定输入属于哪个类别或群组。大语言模型可以从输入信息中抽取特征,并将其分类到适当的类别。包括情感分析(把文本分为积极,消极,或中性)图像分类(识别图像中的对象或景色)语言识别(识别特定的语言类型或方言)等。
总结任务:从大量的信息中抽取关键点并生成一个简洁的总结。包括文章摘要(把长篇文章精简为几句关键信息)会议记录总结(将长时间的会议记录转化为主要讨论点)等。大语言模型能够理解和提炼信息,提供简明、准确的总结。
改写任务 :指将信息或内容在保持原意的情况下重新表述。包括文本改写(例如,将复杂的语句转化为易懂的语言)语义等价句生成(例如,用一种新方式表达同一思想)语言翻译等。大语言模型能够理解语义,从而在改写时保持原始信息的准确性与合理性。
那目前为止,什么样的参数量才能被称为大呢?一般来说参数量大指的是 $7b - 100b + (b$ 指的是billion,单位为十亿),也就是70亿~1000亿参数量。
简单来说,参数其实就是一个浮点数,例如3.1415,而在计算机内,使用2字节或者4字节来存储浮点数类型的数据,70亿个参数的大小也仅仅为28G。
那么一坨28G的数据为什么能和我们进行流畅对话呢?
2. 大语言模型中的Token、词表与预测
在大语言模型中,计算长度的依据并不是字符,而是Token,Token其实就是文本片段,可以是字、词、甚至是半个字或者三分之一个字。
比如GPT- 3.5- 16K模型的上下文长度是16K,意思就是单次对话的最多可以包含16,000个 Token(文本片段)
不同模型的Token是不一样的,对于一个仅支持英语的模型,它的Token可能非常少,仅包含a- z26个字母、逗号、句号、空格等标点符号。
而汉字字词更多,语义会更复杂,所以包含的Token会更多,在一些支持多语言的模型中,Token会包含各种符号、单词、单词片段等,所以往往会有几十万个Token甚至更多(GPT模型的Token数更是达到了 $30+$ 亿,所以大模型会有各种可能的输出)
将Token按顺序排列组成的表叫词表,在词表中每个Token都有其对应的id,一般从0开始,如下
"vocab": {
// 开头是一些特殊符号
"<unk>": 0,
"<|startoftext|>": 1,
"<|endoftext|>": 2,
"<|Human|>": 3,
"<|Assistant|>": 4,
...
// 这是字节token,如果出现不在词表中的特殊符号会回退到字节表示
"<0x00>": 305,
"<0x01>": 306,
"<0x02>": 307,
"<0x03>": 308,
"<0x04>": 309,
...
// 下面是正常的英文token,有_的表示是单词的开头,没有的是单词中间
"ct": 611,
"▁re": 612,
"ve": 613,
"am": 614,
"▁e": 615,
...
// 有中文token出现
"安徽省": 28560,
"▁aliens": 28561,
"▁imagery": 28562,
"▁squeeze": 28563,
"子和": 28564,
...
}有了 Token + 词表,我们就可以来看下大语言模型的工作流程:
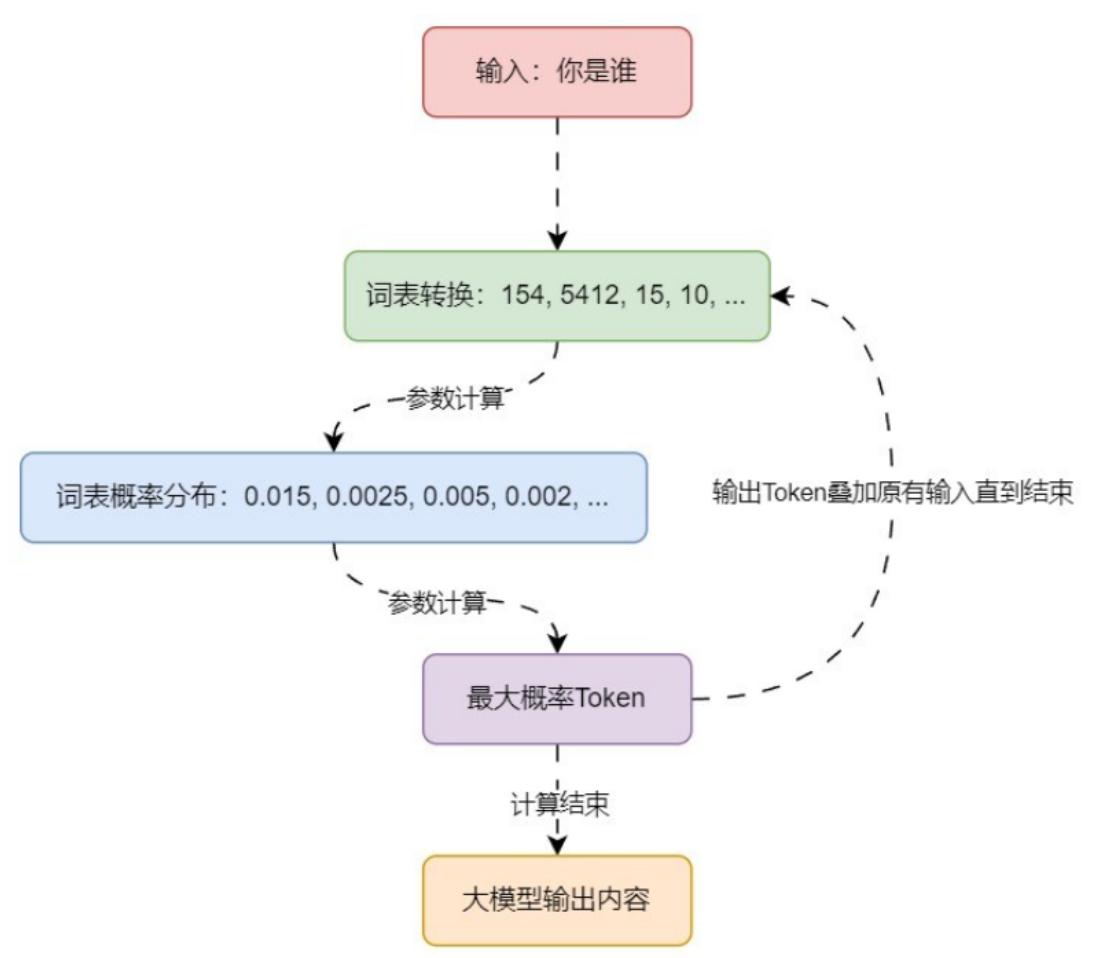
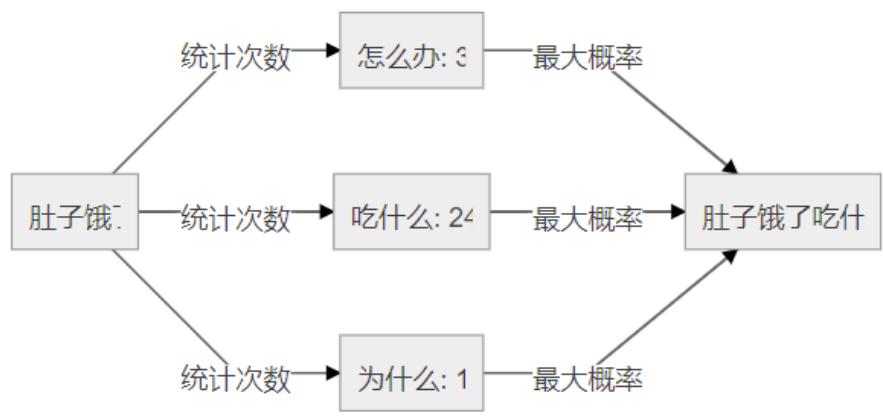
接下来我们从非机器学习的角度来讲讲大语言模型的 Token 预测机制,一种最简单的办法就是基于统计,通过大量数据的统计,找到下一个 Token。例如:采集大量文本进行扫描计算,并记录所有片段的输入以及下一个文本出现的次数,得到一张巨大的分布表。然后将将输入的文本对照分布表查询,找到所有 Token 的出现次数或概率,找到出现次数最大的 Token 即为预测结果。
例如:
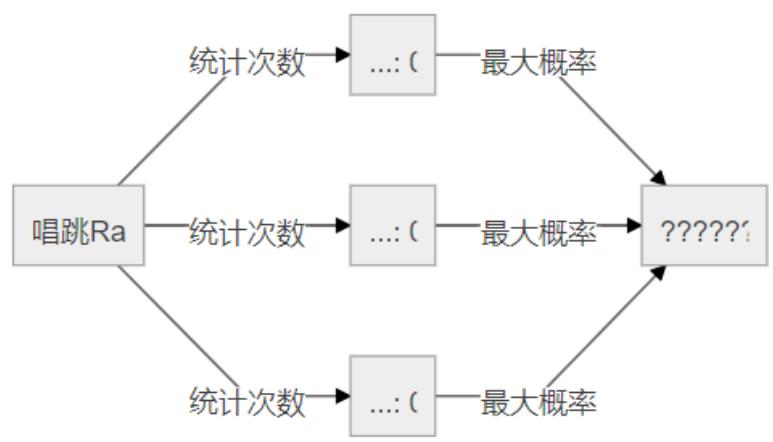
但是基于统计的情况对于没有统计到的片段就无能为力了,比如“唱跳Rap”这个片段并没有在统计中,基于统计的算法会将所有的Token出现次数都设置为0,如下
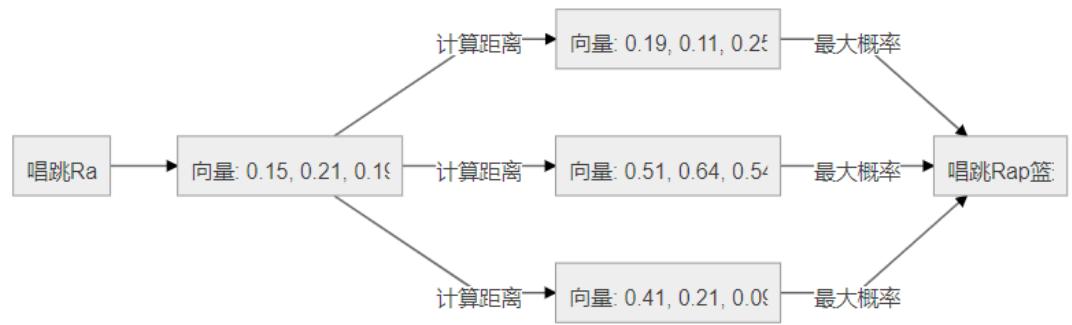
这个时候就可以考虑将输入+词全部转换成向量/文本嵌入通过向量与向量之间的距离越近,看成概率越大来解决这个问题,在实际的模型中,往往会比这个复杂得多,添加向量转换后,整个流程图如下
3. 大语言模型中的训练
训练指的是将大量文本输入给模型,进而得到模型参数,目前LLM训练一般用到了大量文本,一般在2Ttoken以上(2万亿Token)。
这里我们以“程序员的梦工厂”这句话作为训练,来看下整个流程,当然这个流程也是极大地简化了。
初始化模型的所有参数,所以一开始的时候,70亿个参数都是随机初始化的,无论输入什么都会输出随机乱码;
将“程序员的梦工厂”这句话作为LLM的训练预料,并假设每个字都是一个token;
将第一个token输入给模型,即输入“程”;
经过一系列复杂而昂贵的计算后,模型输出了一个随机的概率秒笔,概率最大的可能是“hello”;
正常应该输出“序”,所以错得很离谱,通过计算模型输出和真实的label直接的交叉熵loss,它的输出越接近正确,这个loss越小;
使用梯度下降的方法来调整整个模型的70亿参数,调整过后可以使得下次对于同样输入的情况下,它的输出会“错得少一点”,这样就完成了一个step的训练;
第2个step中,我们将输入“程”+“序”两个token给模型,并期望模型输出“员”这个token,根据模型的输出和“员”的差异,确定loss的大小并通过反向传播来调整模型参数。
以此类推。
一次经过简化版的训练流程如下

如此重复万亿次,一个大语言模型的训练就完成了,前面讲过,目前LLM一般的训练数据量在2T token左右,于是这个过程就是重复2万亿次。70亿参数的一次计算其实计算量已经非常大了,再乘上2万亿。这也就是大模型一次训练的成本都在成百上千万的原因