26| 生产者收到写入成功响应后消息是否一定不会丢?
26| 生产者收到写入成功响应后消息是否一定不会丢?
消息丢失问题是消息队列系统中的关键挑战,与之相对的就是我们常说的可靠消息。这两个概念本质上是一枚硬币的两面。在实际工作中,一旦碰到消息丢失这种棘手问题,想要定位原因往往让人头疼不已。从理论角度看,要彻底理解消息丢失,你必须对整个消息流转链路有个透彻的认识——从生产者发出到消费者消费的每一环节。
今天我就带你走一遍消息的完整旅程,看看从发送到消费的每个节点上,我们需要做些什么才能确保消息平安到达目的地。最后,我还会介绍一个基于Kafka的消息回查方案,帮你在面试中脱颖而出。先从基础知识开始吧。
Kafka的主从机制与ISR列表
在Kafka的世界里,消息存储在所谓的分区中。为了防止存储消息的服务器突然挂掉,每个分区实际上采用了主从架构。换句话说,不同分区之间是平等关系,而每个分区内部则是由一个主分区和多个从分区组成的小团队。
不管是主分区还是从分区,它们都托管在叫做broker的服务器上。在部署时,我们通常遵循一个原则:一台broker上最好只放一个主分区,但可以同时托管其他主分区的从分区。

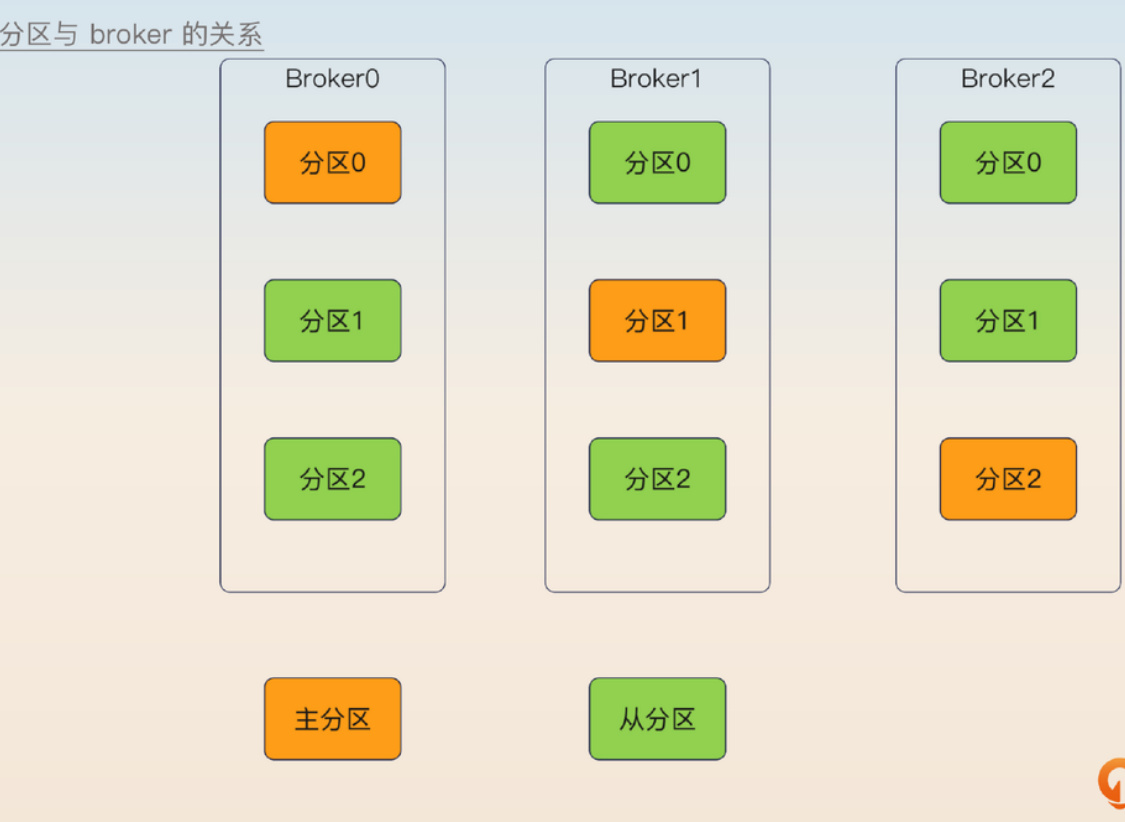
这种配置思路其实很好理解,有点像"不把鸡蛋放在一个篮子里"的道理。通过把主分区分散在不同的broker上,我们可以避免一台服务器崩溃时影响到多个主分区。
写入机制探秘
结合我们之前讨论过的MySQL写入机制,你可能已经猜到,当我们谈论写入消息时,既可能是指写入主分区,也可能是指写入主分区后再同步到部分从分区。
Kafka在这方面设计得相当灵活,它把决定权交给了生产者。控制这个行为的参数叫做acks,它有三种可能的取值。
• 0:也就是常说的"发完就忘"(fire and forget),意思是发送后不管结果如何,不关心broker是否收到,是否成功持久化,是否完成了主从同步,统统不管。
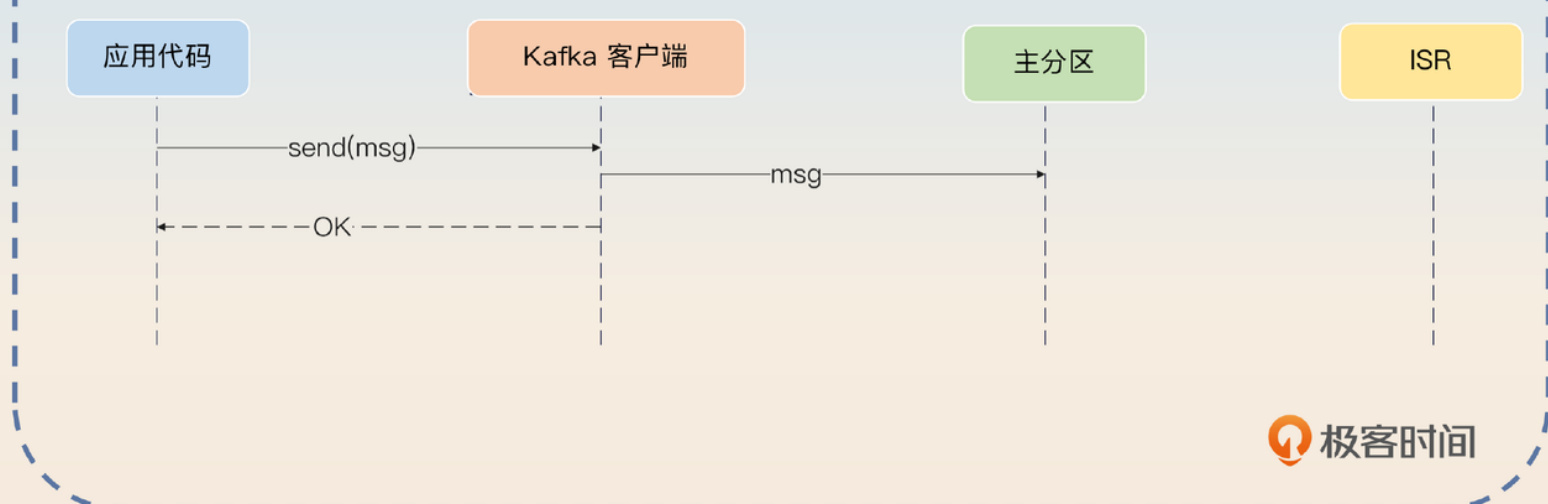
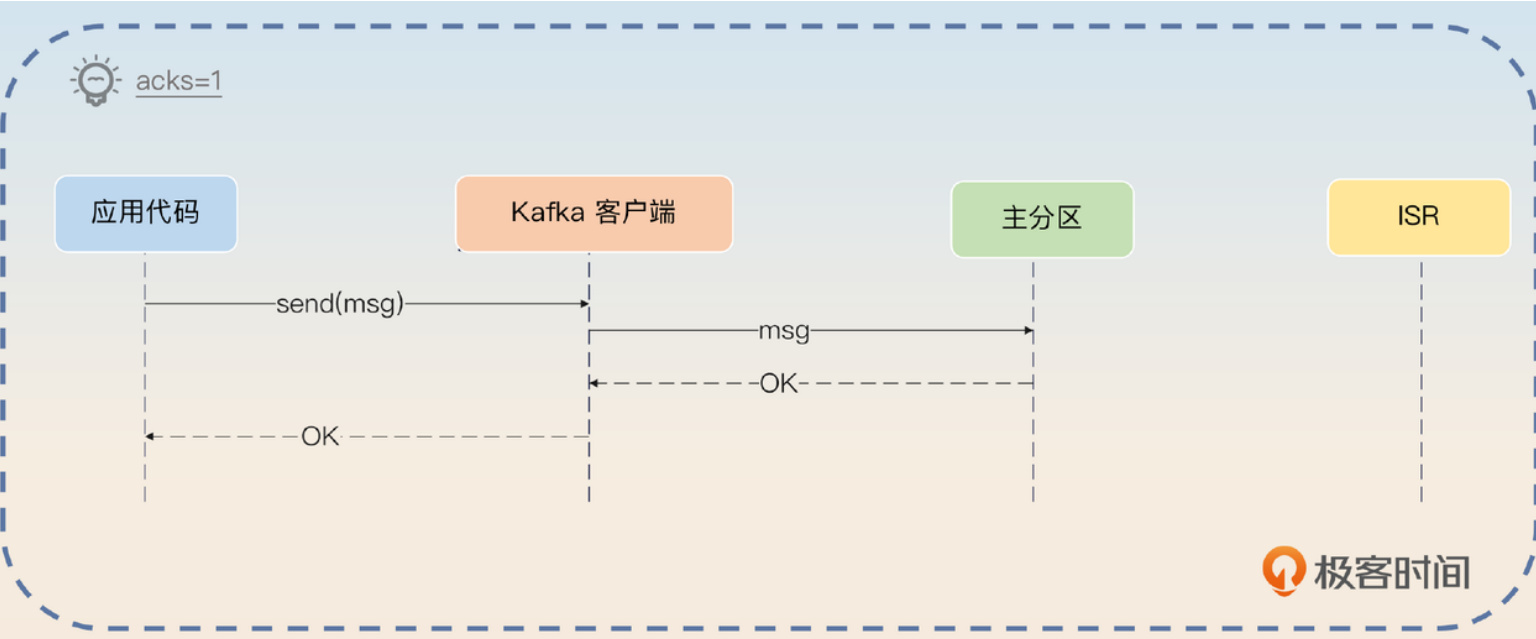
• 1:当主分区成功写入数据后,就认为发送成功了。
• all:不仅要写入主分区,还必须同步到所有ISR成员才算完成。
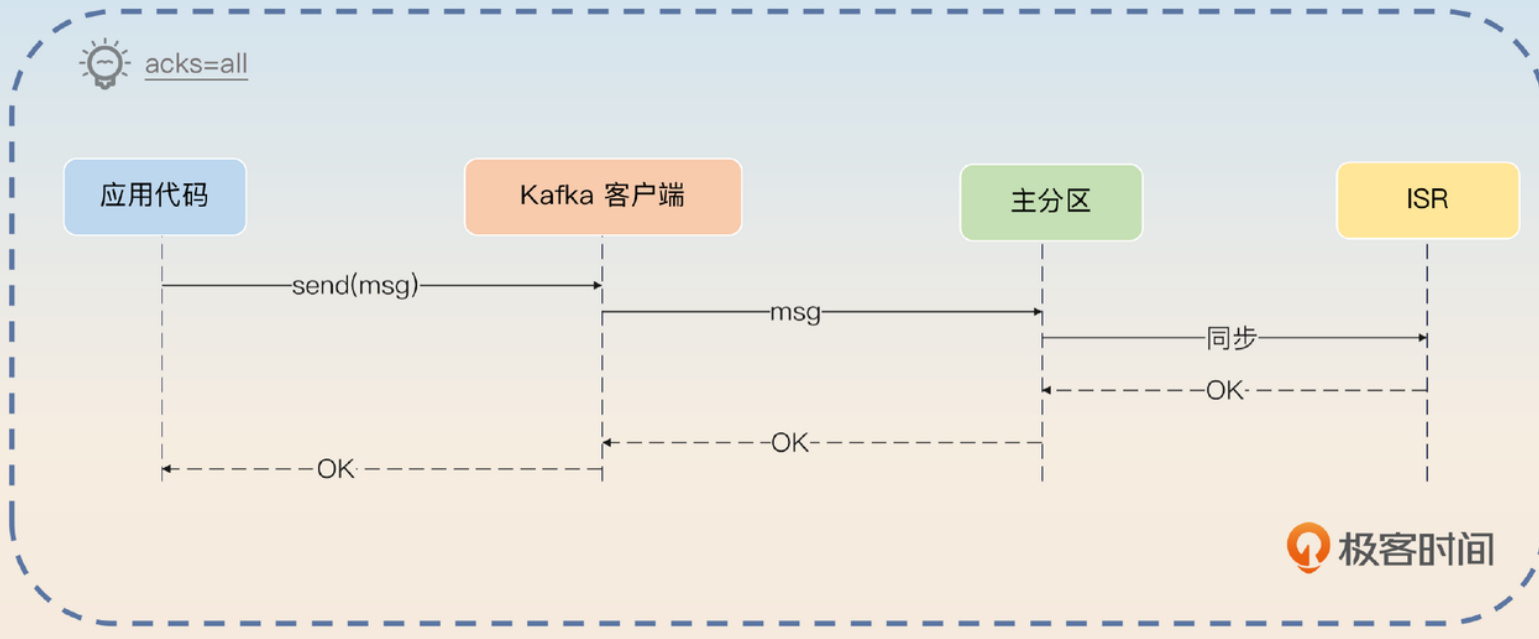
这里你碰到了Kafka中另一个核心概念:ISR。
ISR是个啥
ISR(In-Sync Replicas)指的是那些与主分区保持同步的从分区集合。打个比方,假如一个主分区原本有3个从分区小弟,但因为网络问题,其中一个从分区跟不上主分区的节奏,无法及时同步数据,那么对这个主分区来说,它的ISR就只剩下另外2个忠实小弟了。
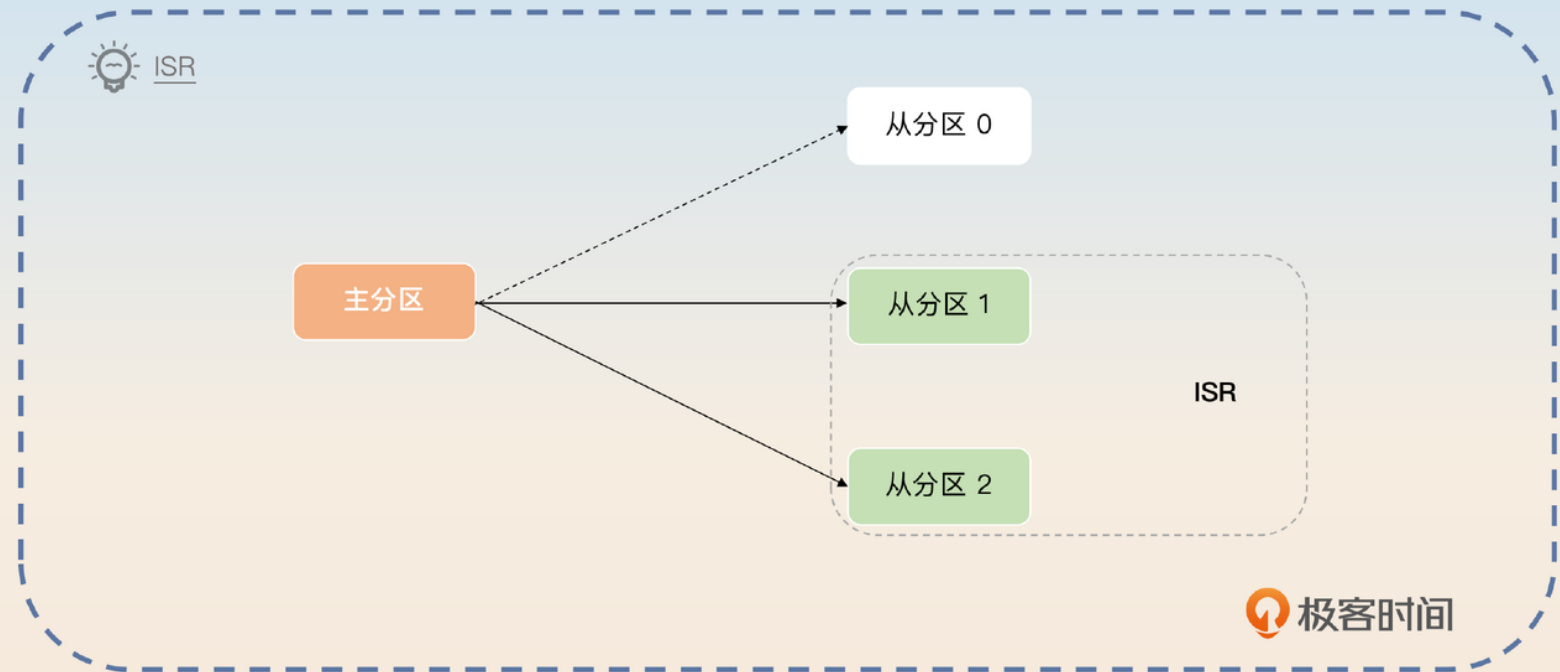
那么,Kafka对ISR里面必须有多少个分区有没有要求呢?比如,我有一个主分区带着11个小弟,我的ISR可以只剩下一个小弟吗?
确实可以,Kafka允许通过min.insync.replicas参数来设置。举例来说,如果你设置min.insync.replicas=2,就意味着ISR中至少要有两个从分区。如果数量不够,那么当生产者使用acks=all时,发送消息会直接失败。与ISR相对的概念是OSR,指的就是那些掉队的、不在ISR中的分区集合。
消息可能丢失的各种情况
为了让你理解后面要讲的各种保障措施,我先带你分析一下消息从生产到消费的完整链路中,到底哪些环节可能导致消息悄悄溜走。
生产者发送环节
了解了acks参数后,我们首先能想到的消息丢失场景是:生产者把acks设成了0,然后发送消息。这种情况下,生产者拿到了客户端返回的成功响应,但实际上broker可能根本没收到消息,或者收到了但处理时遇到了bug。
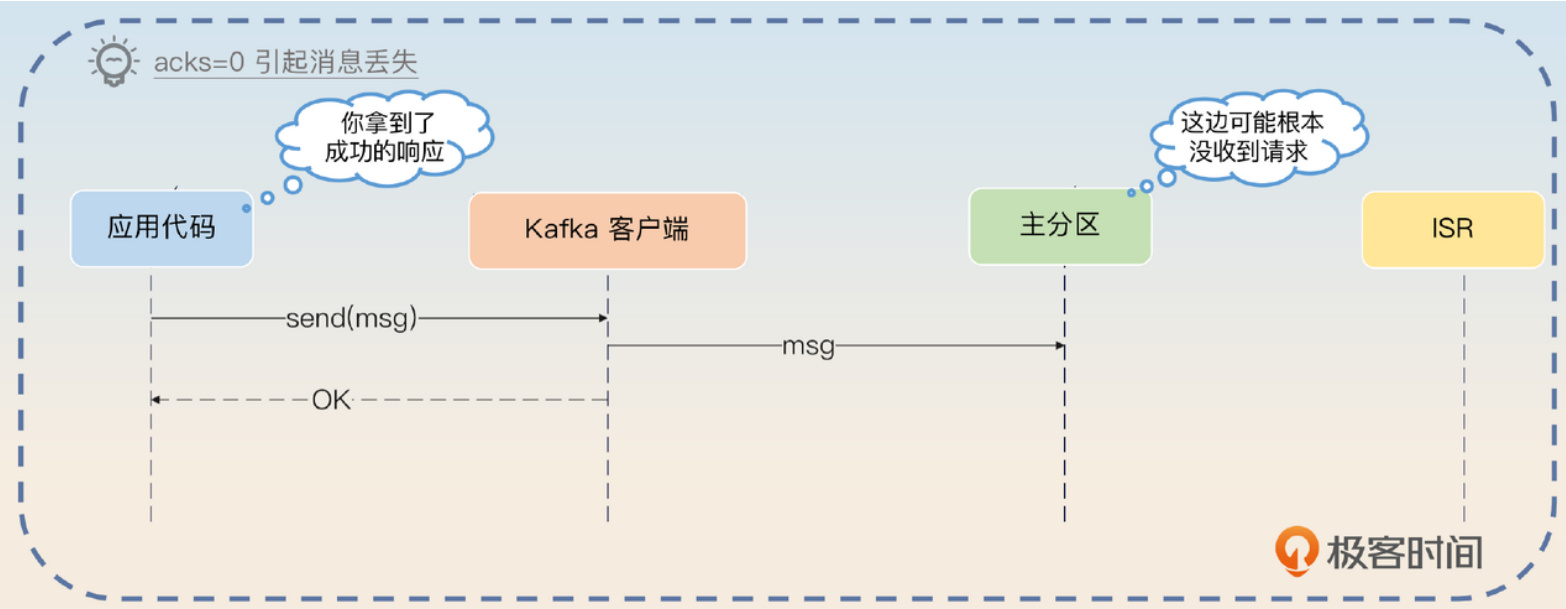
如果你开启了批量发送功能,而且批次比较大,还可能出现另一种情况:Kafka客户端连请求都没发出去,服务就整个崩溃了,这种情况下消息也会丢失。
那么,主分区真的写入成功就万无一失了吗?显然不是,因为你还得考虑主从同步的问题。
主从同步环节
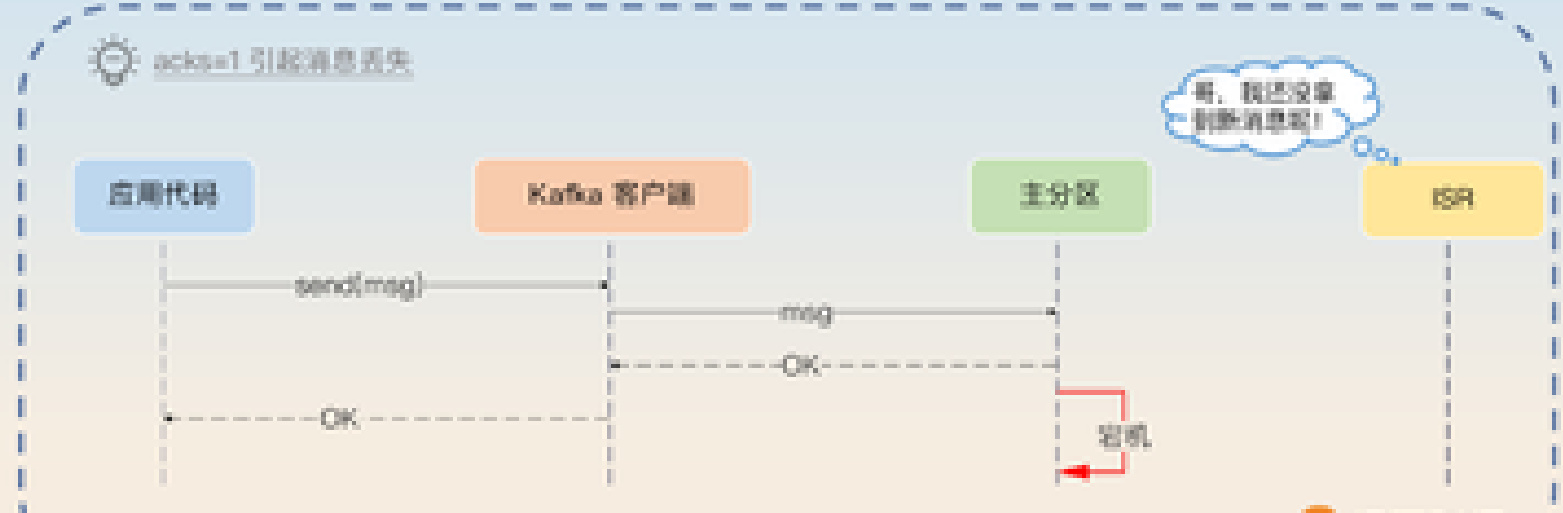
我们注意到,当acks=1时,只要求写入主分区就算成功。因此,如果在写入主分区后,主分区所在的broker立刻崩溃了,然后系统重新选举新的主分区,不管选中哪个从分区,它都会缺少这条关键消息。
极客时间
看起来,只要用acks=all就绝对安全了,对不对?其实也未必,因为Kafka还有一种叫"unclean选举"的机制。在允许unclean选举的情况下,如果ISR中一个分区都没有了,Kafka会选择第一个可用的从分区作为主分区,即使它可能不在ISR中。
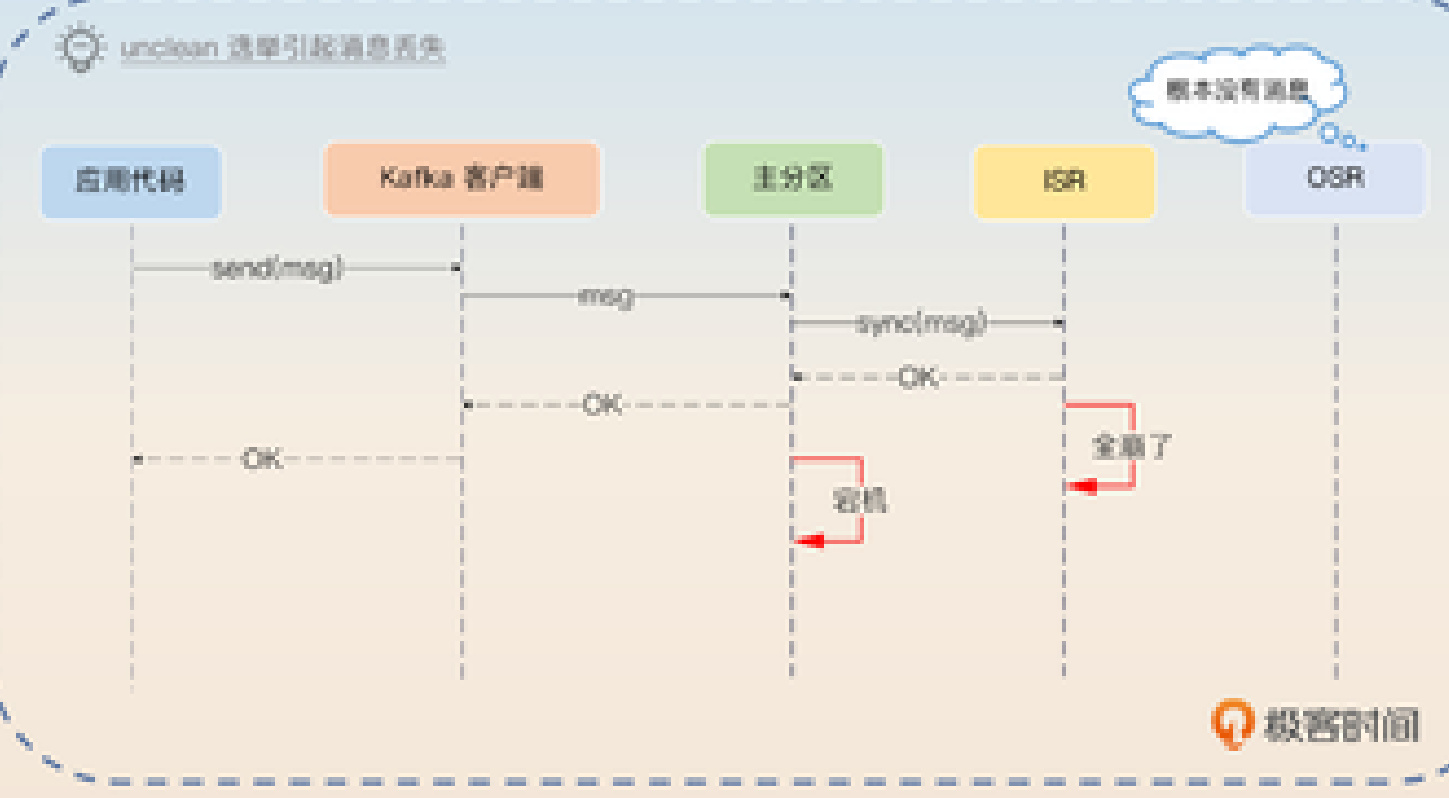
这种unclean选举机制的初衷是为了保证Kafka的可用性,让系统能够继续工作,同时等待从分区重新加入ISR。不过,通过unclean选举产生的新主分区可能会缺少一部分数据。那么,如果我设置acks=all并且禁用unclean选举,是不是就绝对安全了呢?
实际上还是不够,因为你还漏了一个关键问题:数据的持久化落盘。
数据落盘环节
之前讨论MySQL时我们提到过写入语义,涉及到redo log和binlog的刷盘问题。在Kafka这边同样存在这个问题。
当acks=1时,主分区返回成功消息,但此时数据可能还躺在操作系统的page cache里,没真正写入磁盘。
同样,当acks=all时,主分区返回成功消息,不管是主分区还是ISR中的从分区,消息都可能还停留在page cache中,等待刷盘。
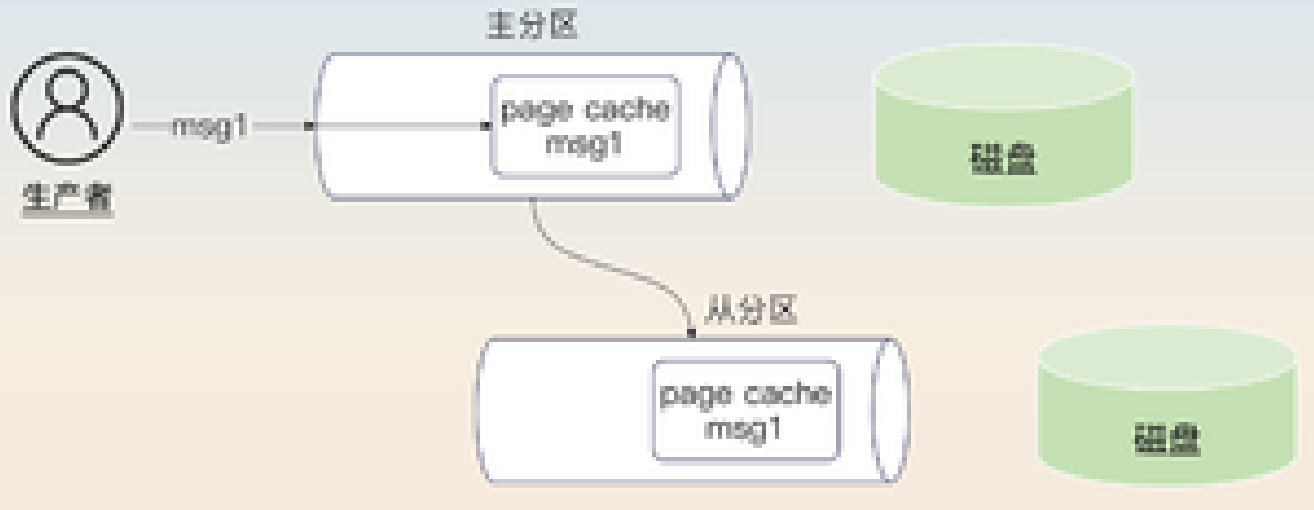
在Kafka中,控制刷盘行为的参数主要有三个:
• log.flush.interval.messages:控制积累多少条消息就强制刷盘,Kafka会在写入page cache时顺便检查一下。
• log.flush.interval.ms:设置多少毫秒就刷新数据到磁盘。
• log.flush.scheduler.interval.ms:设置多少毫秒检查一次是否需要刷盘。
后两个参数通常是搭配使用的。举个例子,假如log.flush.interval.ms设为500,而log.flush.scheduler.interval.ms设为200。这意味着Kafka每隔200毫秒检查一次,如果距离上次刷盘已经过了500毫秒,那就触发一次刷盘操作。
如果同时设置了log.flush.interval.messages和log.flush.interval.ms,那么只要满足其中任一条件,Kafka就会执行刷盘。
给你个小技巧记忆这些参数:Kafka要么是"定量刷"(积累一定数量),要么是"定时刷"(达到时间阈值)。不过,Kafka的维护者通常不建议调整这些参数,他们更推荐依靠副本机制(从分区)来保证数据不丢失。
消费者提交环节
消费者提交偏移量但实际未消费完成,也算一种变相的"消息丢失"。典型场景是线程池形式的异步消费:消费者线程拿到消息就直接提交偏移量,然后丢给工作线程去处理。万一在消息转交前或者工作线程处理过程中消费者崩溃了,这条消息虽然标记为"已消费",实际上却没被处理完,相当于丢失了。
面试前的准备工作
面试前,最好在公司内部收集一些跟消息丢失相关的案例材料:
• 你或同事有没有因为消息丢失导致的线上故障?原因是什么?最后怎么解决的?或者采取了什么措施防止再次发生?
• 公司核心业务的topic分区数量是多少?每个主分区配了几个从分区?
• 你们业务发消息是同步还是异步?acks参数设置是什么值?
• Kafka的三个刷盘参数配置是什么?如果做了修改,为什么要改?
• 有没有遇到必须确保消息发送成功的场景?在这些场景下怎么确保业务方一定能把消息发出去?
学习Kafka这类框架时,要特别注意它们的写入语义。如我在MySQL部分提到的,多看几个框架后你会发现,不同框架在写入语义上的设计其实差异不大。大多数框架的设计理念非常接近,平时多总结这些共性,能帮你在面试中展示出思考的深度和广度。
如果面试官问到以下问题,你可以考虑把话题引向消息丢失:
• 问到延迟消息时,介绍完Kafka支持延迟消息的方案后,可以提及你用类似手段实现了消息回查。
• 问到刷盘相关问题(如MySQL的redo log)时,可以提到Kafka也有类似参数。
• 问到分区表、分库分表时,可以说明你用这些技术解决过延迟消息和消息回查问题。
• 问到主从模式时,可以介绍主从模式下的写入语义。
面试官也可能直接问消息丢失相关问题:
• 业务中遇到过消息丢失问题吗?怎么解决的?
• 发送消息时acks怎么设置的?为什么选这个值?异步消费时如何避免"已提交但未消费"的情况?
• 什么是ISR?什么情况会导致分区被移出ISR?
回答思路总览
面试时,你需要从整体上系统性地阐述你的方案。这种全面的思路能展示你对话题的深入理解。
在我们公司的核心业务中,消息绝对不能丢是底线。这意味着发送方必须确保消息发出去,消息队列必须保证消息安全存储,消费者也必须正确消费这个消息。因此,我们在这三个环节都做了周密的工作来确保消息万无一失。
确保发送方一定能发出消息
这个问题本质上涉及到本地事务。你可以把相关场景抽象为执行业务操作和发送消息这两个步骤。
从业务角度看,我们需要确保这两个步骤要么都不执行,要么都执行成功。这其实是个分布式事务问题,主要有两种解决方案:本地消息表和消息回查。先来看本地消息表方案,它在实践中使用广泛,思路相对直接。
在我们系统中,发送方采用的是本地消息表方案。简单来说,就是在执行业务操作时,先在本地消息表中记录一条待发消息,作为一个本地数据库事务。然后立即尝试发送消息,如果成功了,就把本地表中对应记录删除或标记为已发送。
如果发送失败,可以立即重试。同时,我们还有个异步补发机制,定期扫描本地消息表,找出那些已经等待一段时间(比如三分钟)但还没发送成功的消息进行补发。
这个异步补发机制,简单理解就是有个线程定期扫描数据库,找出那些需要发送但还没发出去的消息。具体实现上,就是执行类似这样的SQL:
1 SELECT $\star$ FROM msg_tab WHERE create_time $\angle\cdot\angle$ now() - 3min AND status $\mathbf{\Sigma}=\mathbf{\Sigma}$ '未发送'
2 #找出三分钟前还没发送出去的消息,然后补发。整个流程如下图所示:
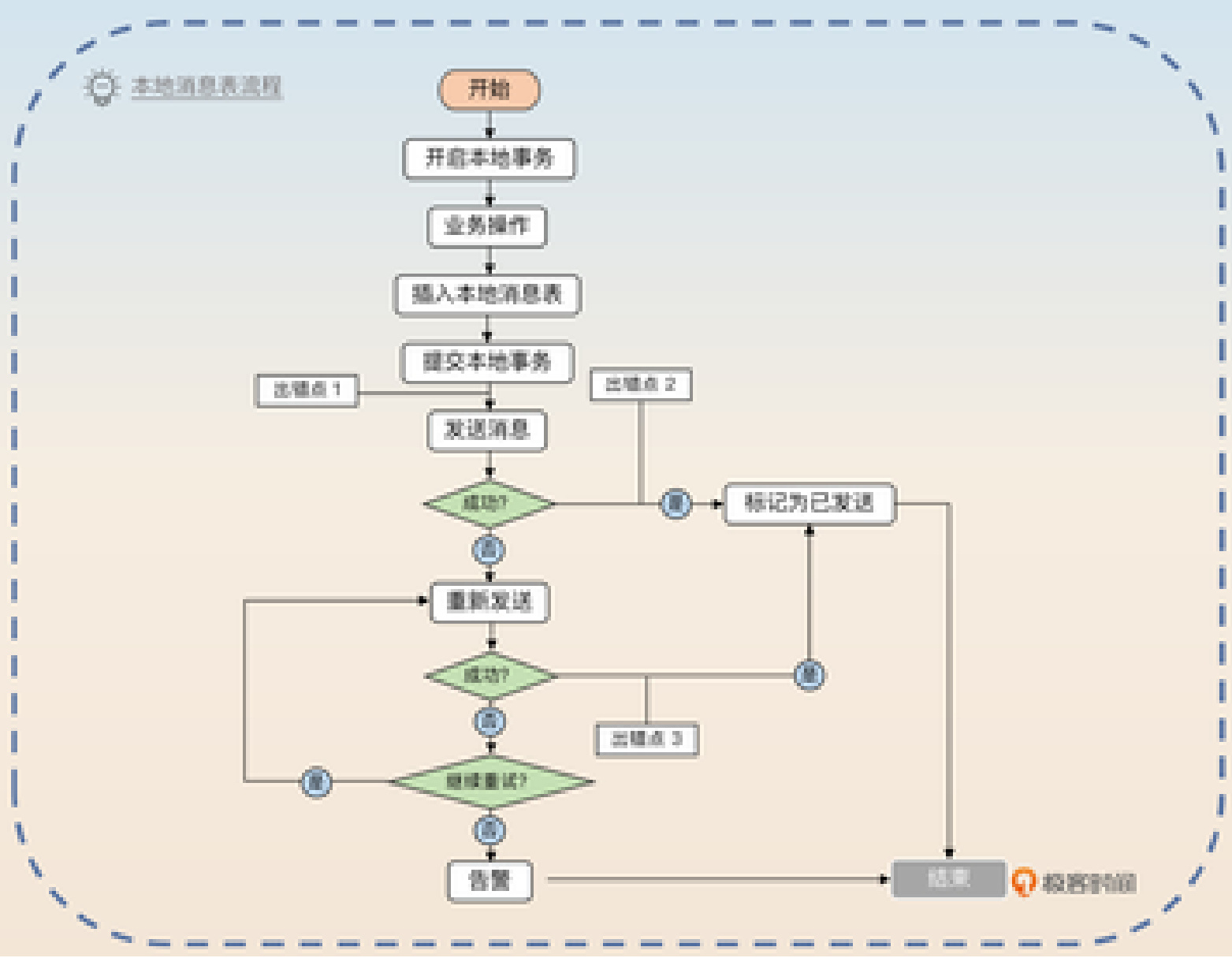
图中标注了三个容易出错的地方,面试官很可能会追问这些点:
- 如果事务已提交但服务器突然宕机,也没关系。异步补发机制会找出这条消息并补发。
- 如果消息发送成功但还没来得及更新数据库中的状态,也没问题,异步补发机制会再找出这条消息发一次,最多就是重复发送。
- 如果在重试过程中发送成功但未更新状态,同样依靠异步补发机制处理。
注意到这三点都依赖异步补发机制。当然,任何重试都要控制好重试间隔和次数。在我们的本地消息表中,额外增加了字段来控制重试策略。
我们的消息表至少包含两个关键字段:一个存储消息体内容,另一个负责重试机制控制(如重试间隔、已重试次数、最大重试次数)。其他字段可以根据需要自行添加,不是重点。
最后,可以总结升华一下,展示你对分布式事务的深刻理解:
这种方案本质上是把分布式事务转变成"本地事务+补偿机制"的组合。在我们的例子中,分布式事务要求执行业务操作并发送消息,我们将其转化为一个本地事务(包含业务操作和记录下一步计划),然后补偿机制负责查看本地事务的结果,找出需要执行但未成功的下一步(即发送消息)并执行它。
实际上,很多分布式事务问题都可以用"本地事务+补偿机制"来解决,这是一种实用的设计模式。
确保消息队列不丢消息
发送者拿到了消息队列的响应,就意味着消息已被接收。根据前面的分析,要确保消息队列不丢消息,acks应该设为all,并且禁用unclean选举。
考虑到刷盘问题,还需要合理设置log.flush.interval.messages、log.flush.interval.ms和log.flush.scheduler.interval.ms这三个参数。
在我们公司的关键业务中,我通常把acks设为all并禁用unclean选举,确保消息安全到达队列且不会丢失。同时,我们公司对log.flush.interval.messages、log.flush.interval.ms和log.flush.scheduler.interval.ms三个参数的配置值分别是10000、2000和3000。
理论上,这种配置下消息丢失的概率已经非常低了。唯一的可能是消息队列完成主从同步后,主分区和ISR中的从分区都没来得及刷盘就同时崩溃了,才会导致消息丢失。这种极端情况下,只能靠人工干预补发消息了。
你也可以从优化角度来描述实际案例:
早期我们就遇到过消息丢失的血泪教训。有个核心业务把acks设成了0,结果某天消息队列崩溃后,等恢复时发现消息全都找不回来了。因为这是个核心业务,我们立即把acks改成了all。之后即便消息队列再出问题,也再没出现过消息丢失的情况。
当消息队列能确保消息安全后,你要做的就是确保消费者能正确消费。
确保消费者不漏消费
这点通常不需要额外工作,除非你用了异步消费机制,这部分可以参考消息积压那节课提到的异步消费方案。
简单介绍一下就足够了:
确保消费者不漏消费消息,大多数情况下不需要特别处理,但如果用了异步消费就要格外小心。比如我们的A业务用异步消费提高处理速度,我们通过批量消费、批量提交的方式,既保证了处理效率,又避免了消息漏消费的风险。
这里可以顺势引导话题到异步消费,然后提及消息积压问题,掌握面试节奏。
亮点方案:Kafka上的消息回查机制
所谓消息回查机制,是指消息队列允许发送者先发一个准备消息,包含消息内容但不会立即投递给消费者。等业务操作完成后,发送者再发一个确认请求,此时消息队列才会把消息转交给消费者。
显然,这是两阶段提交的简化应用,因此也被称为事务消息。
但这种机制有个问题:如果业务成功了,但确认请求没发出去怎么办?这就是消息回查的用武之地——当消息队列长时间没收到确认请求时,会反过来询问发送方,这个消息是否应该交给消费者。
消息回查依赖消息队列的支持。RocketMQ原生支持,但Kafka和RabbitMQ都不支持。那么如何在Kafka基础上实现消息回查呢?
结合图片,简要说明整个流程:
我们公司用的是Kafka,它不原生支持消息回查,所以我设计了一个系统来实现这个功能。
基本步骤是这样的:
- 应用代码首先把准备消息发送到一个特殊的topic(look_back_msg)。消息中包含目标业务topic、消息体、业务类型、业务ID、准备状态和回查接口信息。
- 我们的回查中间件消费这个特殊topic,并把消息内容存入数据库。
- 应用代码执行完业务操作后,再发一条消息到同一个特殊topic,带上业务类型、业务ID和提交状态。如果业务执行失败,则使用回滚状态。
- 回查中间件查询对应的消息内容,然后转发到真正的业务topic。
这个方案处处是亮点,我们一一分析。
亮点一:回查实现
如果业务操作完成后没有发送提交消息,回查中间件就需要出马了。通常,回查中间件会异步扫描长时间未提交的消息,然后回查业务方。
关键是回查中间件如何与应用代码通信。理想的设计应该是可扩展的,支持HTTP和RPC等多种回查方式。
在我设计的系统中,如果业务方没发提交消息,回查中间件会找出这些长时间未提交的消息,执行回查。中间件通过准备消息中的回查接口配置来调用业务方。我设计了一套通用机制,同时支持HTTP和RPC调用。
对HTTP调用来说,业务方需要提供回查URL。对RPC调用,业务方需要实现我提供的回查接口并提供服务名。回查时,我会带上业务类型和业务ID,业务方需要告知这个消息是否可以提交。
举个HTTP回查的例子,假设回查一个订单业务,请求大概是这样:
1 method: POST
2 URL: https://abc.com:8080/order/lookback
3 Body: {
4 "biz_type": "order",
5 "biz_id": "oid-123"
6 }业务方返回的响应:
1 Body: {
2 "biz_type": "order",
3 "biz_id": "oid-123",
4 "status": "提交" //如果业务没成功,那么可以是回滚
5 }如果是RPC接口,回查中间件可以定义一个统一接口,要求所有业务方实现:
1 type MsgLookBack interface{
2 LookBack(bizType string, bizID int) Status
3 }业务方提供服务名(如abc.com.order.msg_look_back),回查中间件通过RPC泛化调用发起请求。如果你不熟悉泛化调用,可以说目前只支持HTTP回查,但计划扩展到RPC。
这个设计展示了你解决复杂业务问题的系统设计能力。
亮点二:数据存储
这部分与延迟队列实现类似。可以使用分区表、交替表或分库分表来存储回查消息。
具体细节可参考延迟队列内容,这里用分区表举例:
为确保回查机制高性能高可靠,我们使用了分区表。按时间分区,历史分区可快速归档,因为回查机制的数据库只是临时存储消息。随着业务扩展,这部分也可以考虑按业务topic进行分库分表。
亮点三:消息顺序保证
你是否考虑过一种情况:中间件有可能先收到提交消息,后收到准备消息?
回查机制要求必须先收到准备消息,再收到提交消息。解决方案很简单:
这个方案要求准备消息和提交消息必须有序,即同一业务的准备消息一定要先于提交消息到达。解决方法很直接:发送时要求业务方按业务ID计算哈希值,然后对分区数取余,得到目标分区。
这里你可以顺势引导话题到消息有序性问题。
总结回顾
最后总结一下今天的内容。为了理解消息丢失问题,我们先学习了Kafka主从同步与ISR的基本概念,然后系统分析了各环节可能导致消息丢失的场景。面试时,应沿着生产者→消息队列→消费者这条链路,解释每个环节如何确保消息不丢失。
• 生产者端要确保消息一定被发出,可以用本地消息表或消息回查机制。
• 消息队列配置要注意acks参数,以及三个刷盘参数:log.flush.interval.messages、log.flush.interval.ms和log.flush.scheduler.interval.ms。
• 消费者端只需注意异步消费的可能问题。
Kafka本身不支持消息回查,所以我们可以借助MySQL来实现。核心思路是借鉴两阶段提交,要求业务方先发准备消息,再发提交消息。如果没收到提交消息,就回查业务方。三个关键点是:回查实现方式、数据存储策略、准备消息和提交消息的有序性保证。
最后提醒一点,前面多次提到重试必然会导致重复消费,这要求消费者必须实现幂等处理。
结合延迟消息,我们有两种增强Kafka功能的方案。如果你有精力,可以尝试将它们融合,做成一个开源框架。这类项目既能锻炼系统设计能力,又能在面试中展示你的技术深度。
思考题
最后留两个问题请你思考:
• 在Kafka回查机制中,如果回查中间件成功把消息转发到业务topic,但标记为"已发送"失败了,会有什么后果?
• 如果把Kafka回查机制中的关系型数据库换成Redis,有哪些优缺点?
欢迎在评论区分享你的想法,也欢迎把这篇文章分享给需要的朋友,我们下次再见!